


今天给大家展示的是一份从2007到2020年的各个省份各个季度的离婚情况表,表结构如下(截取部分):
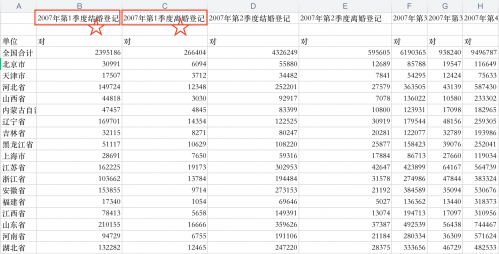
我们通过操作这张表,学习DataFrame的索引、切片和一些算术操作。我们知道DataFrame是一个二维的数据结构,我们学习过Series的索引和切片,只不过它是一个一维的。但是两者在使用上还是很类似的。

#### 索引
DataFrame是否也有这些呢?我们通过**2007-2020全国结婚离婚数据.csv**这个数据表来去看一下。
```python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('2007-2020全国结婚离婚数据.csv')
# 因为在列名下面有一个空行我们删除掉
data = data.dropna()
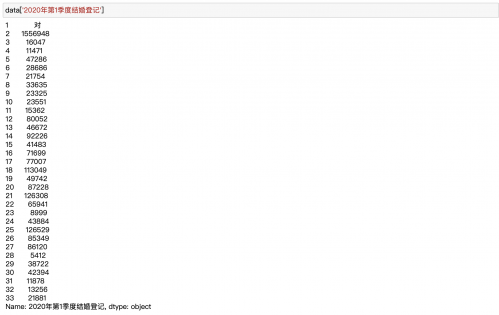
# 获取2020年第一季度结婚数 (即某一列数据)
data['2020年第1季度结婚登记']
data数据如下所示:

# 获取北京市2007-2020年的所有数据(即一行数据)
data[3] # 使用行标签3是否可以呢?
```
此时有报错:KeyError: 3,因此对于DataFrame来说,我们不能直接使用索引值访问行。
所以我们分别从**行和列**两个方面给大家介绍索引访问,先来看一张表格
| | 显式访问 | 隐式访问 |
| ---- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| | 即使用index的值进行索引(如果在读取csv,excel文件的时候没有指明列名,则默认是数字1~n) | 使用整数作为索引值(从0开始,默认向后数) |
| 行 | df.loc[行的名字] **获取单行** 如: df.loc[3] df.loc['北京市'] | df.iloc[row_index] **获取单行** 如: df.iloc[2] |
| | df.loc[[行名1,行名2,行名3,....]] **获取不连续多行** 如: df.loc[[3,4,5,6]] df.loc[['北京市','天津市','上海市']] | df.iloc[row_index_list] **获取不连续多行 ** 如:df.iloc[[2,3,7,9]] |
| | df.loc[行名1:行名2] **获取连续多行** 如:df.loc['北京市':'吉林省'] 但是行也可以按照如下形式获取: df['行名1':'行名2':'步长'] 指定步长获取 | df.iloc[start:end] **获取连续多行 ** 如:df.iloc[3:9] |
| 列 | df[列名] **单列访问** 如:df['2020年第1季度结婚登记'] | df.iloc[:,col_loc] **单列访问** 如:df.iloc[:,3] |
| | df[[列名1,列名2,....]] **不连续多列访问** 如:df.[['2020年第1季度结婚登记','2020年第2季度结婚登记']] | df.iloc[:,col_loc_list] **不连续多列访问** 如:df.iloc[:,[3,5,7]] |
| | | df.iloc[:,start:end:step] **连续多列访问** 如:df.iloc[:,3:8] 如果获取的指定某些行或者某些列可以按照如下方式: df.iloc[row_start:row_end:step,col_start:col_end:step] |
**显式访问**具体效果展示:
```python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 将表格的第一列设置为行索引,添加index_col=0
data = pd.read_csv('2007-2020全国结婚离婚数据.csv',index_col=0)
data = data.dropna()
# 显式获取指定列
col1 = data['2007年第1季度结婚登记']
print(col1)
# 显式获取指定行
row1 = data.loc['上海市']
print(row1)
# 显式获取多个指定列
col_list = data[['2007年第1季度结婚登记','2007年第2季度结婚登记','2007年第3季度结婚登记']]
print(col_list)
# 显式获取多个指定行
row_list = data.loc[['北京市','上海市','天津市']]
print(row_list)
```

我们知道隐式索引,行和列都是使用默认的整数作为索引值(从0开始,默认向后数),即
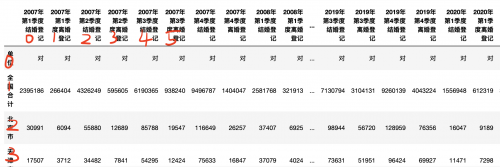
对于数字我们是看不到的,所以我们称为隐式。
列的访问使用的是: iloc[行,列] 行或者列位置如果使用【:】则表示获取所有的行或者所有的列。
**隐式访问**具体效果展示:
```
# 单行的获取
row1 = data.iloc[3]
print(row1)
# 多行获取
row_list = data.iloc[[3,5,7,9]]
print(row_list)
# 单列获取
col = data.iloc[:,3]
print(col)
# 多列获取 (不连续的列)
col_list = data.iloc[:,[2,4,6]]
print(col_list)
```
数据比较多,这里就不给大家截图展示了。
更多关于“Python 培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!














 京公网安备 11010802030320号
京公网安备 11010802030320号