


现在直播带货太火了,宋宋最近也在小红书上败家了好几单,身为程序员的宋宋有点不甘心。拿到了一份小红书直播带货榜数据分析下,看一看小红书的卖货实力和用户分析?本案例主要针对DataFrame的数据统计和排序知识点的讲解。

### 数据展示与清洗
首先了解下我们即将使用的数据book.csv(获取数据文末可以网盘下载):
```python
import pandas as pd
import numpy as np
import random
from matplotlib import pyplot as plt
from pyecharts.charts import Boxplot
df= pd.read_csv("book.csv")
df.info()
```
结果:

数据内容如下:
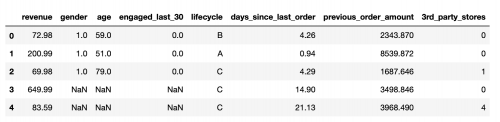
其中每列表示如下:
> 数据说明 这是一个关于用户在小红书购买金额的数据集, 共有29452条数据, 7个变量。
>
> (1) revenue 用户下单的购买金额
>
> (2) 3rd_party_stores 用户过往在app中从第三方购买的数量,为0则代表只在自营商品中购买
>
> (3) Gender 性别 1:男 ,0:女 ,未知则空缺
>
> (4) Engaged_last_30 最近30天在app上有参与重点活动(0:讨论,1:卖家秀的活动)
>
> (5) Lifecycle 生命周期分为A,B,C (分别对应注册A:6个月内,B:1年内,C:2年内)
>
> (6) days_since_last_order 最近一次下单距今的天数 (小于1则代表当天有下单)
>
> (7)previous_order_amount 以往累积的用户购买金额
大家都知道我们在分析数据前都会判断下,是否存在空缺值,重复值、异常值等,即进行数据的清洗。
```python
df.isnull().any()
```

```
df.duplicated().any()
```
结果是:
> True
说明存在空缺值和重复值,于是我们要对这些数据进行处理
```python
# 去除重复数值和缺失数值
df.drop_duplicates(inplace=True)
df.reset_index(drop=True,inplace=True)
df.replace('nan',np.nan,inplace=True)
#把性别、年龄、用户过往中为nan的数值分别用随机、平均值、随机替代
df.fillna(value={"gender":random.choice([1.0,0.0]),"age":round(df["age"].mean(),0),"engaged_last_30":random.choice([1.0,0.0])},inplace=True)
df.head()
```
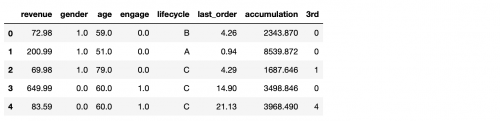
结果:

我们可以发现个别数据的列名比较长,所以我们需要简化部分columns的命名使用rename方法,这样方便我们后续的使用
```python
df=df.rename(columns={
"engaged_last_30": "engage",
df.keys()[5]: "last_order",
"previous_order_amount":"accumulation",
"3rd_party_stores":"3rd"})
```
结果:
更多关于“Python 培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!














 京公网安备 11010802030320号
京公网安备 11010802030320号