


各位朋友们,今天给大家带来的是数据分析的内容。欢迎各位朋友多提宝贵意见哦!
本次分享给大家的是:DataFrame的多层索引及使用。
多层索引是指在行或者列轴上有两个及以上级别的索引,一般表示一个数据的几个分项。比如,下图所示的数据样式:
我们使用的是对美女的颜值投票数据,现在有几位美女分别给他们起了容易记忆的名字,比如:小丽,小芳啊
于是拿着这些照片来到办公区,投票啦!投票啦!大家分成了两组进行投票,男生一组、女生一组,投票的内容就是:漂亮和不漂亮。
于是就有了下面的数据部分:
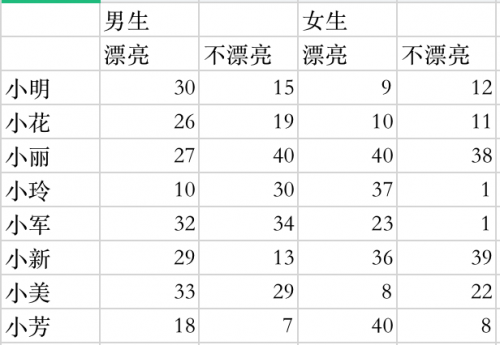
大家发现这个表格数据跟我们常用的不同,那就是列名是有两层的。那这样的数据怎么进行数据分析呢?
```
import numpy as np
import pandas as pd
beauty = pd.read_excel('beauty.xlsx')
beauty
```
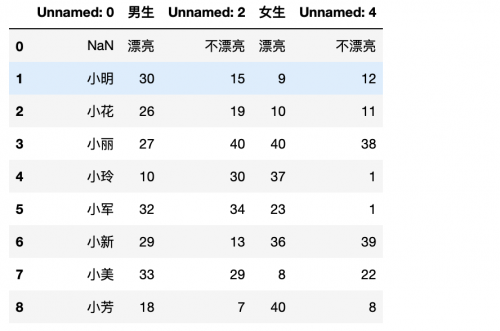
这是什么情况?列名怎么还有Unnamed:0,Unnamed:1这些呢?是我们读取数据的时候没有设置index_col和header属性。
header设置的是列,如果是多列则使用列表,从左到右为0,1,2,...,index_col则是设置的行,用来指定行索引。
```
beauty = pd.read_excel('beauty.xlsx',header=[0,1],index_col=0)
beauty
```
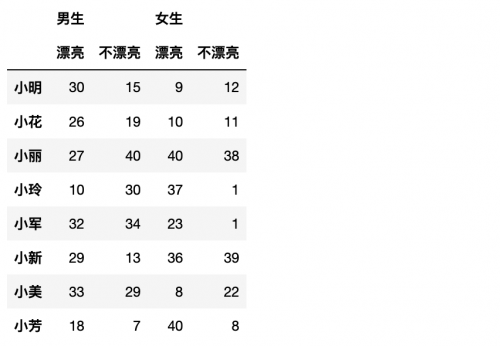
但是要自己创建一个多层索引则有两种方式:分别是隐式和显式的。
### 创建多层索引
方法一:隐式创建,即给DataFrame的`index`或`columns`参数传递两个或更多的数组。我们自己构建一个颜值投票的数据。
```
df1 = pd.DataFrame(np.random.randint(1,30, size=(8, 4)),
index= ['小明','小花','小丽','小玲','小军','小新','小美','小芳'],
columns=[['男生', '男生', '女生', '女生'],
['漂亮', '不漂亮', '漂亮', '不漂亮']])
```
数据虽然有些区别,但是结构是一样的。
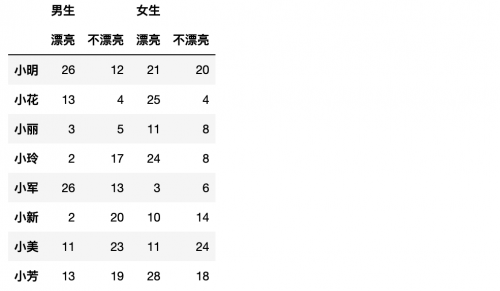
方法二、显示创建,推荐使用较简单的`pd.MultiIndex.from_product`方法。
MultiIndex表示多级索引,它是从Index继承过来的,其中多级标签用元组对象来表示。from_product()从多个集合的笛卡尔积创建MultiIndex对象。
具体的详解:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.MultiIndex.html
```
df = pd.DataFrame(np.random.randint(1,30, size=(8, 4)),
index= ['小明','小花','小丽','小玲','小军','小新','小美','小芳'],
columns=pd.MultiIndex.from_product([['男生', '女生'],
['漂亮', '不漂亮']]))
```
哇!完美!比刚才的还简单了呢?
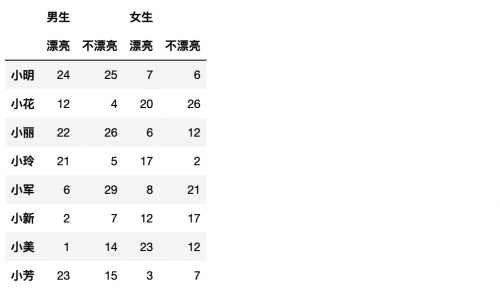
### 检索多层索引
如果检索小美的女生投票如何获取呢?再比如获取小玲的男生漂亮值的投票数是多少呢?
我们一起来看看吧!我们以上面真实的投票数据为例来看一下
```
df.男生
```
结果:

小新的女生投票如何获取呢?这时候就要使用loc[行,列]了,当然如果是小美则就是df.loc[‘小美’,'女生']

当然你也可以获取前3位美女的女生投票,两种方式loc和iloc均可以实现。
```
df.loc[['小明','小花','小丽'],'女生']
```
或者
```
df.iloc[0:3,[2,3]]
```

如果要获取小明,小丽,小军,小美的男女生的漂亮投票数呢?(可以评论区留言哦,我们一起学习有几种获取方式)
### 更改多层索引的层级
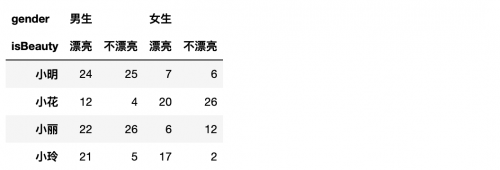
所谓更改多层索引的层级,就是交换下男女生和漂亮和不漂亮的位置。在交换之前我们要知道叫交换的层的名字,但是我们又没有名字,所以我们就要先设置名字,然后交换。
```
df.columns.names = ['gender', 'isBeauty'] # 设置列索引名
# 如果设置index行索引,则可以下面的方式
# df.index.names = ['你的名字']
```
截取部分数据:
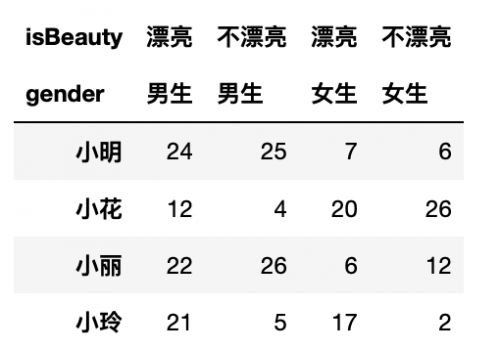
然后就可以交换啦!使用swaplevel

```
df.swaplevel('gender', 'isBeauty',axis=1) # 因为我们是交换列索引,所以axis=1
```
结果:
### 多级索引的值排序
索引名字排序
```
df.sort_index(level=0, axis=1, ascending=True) # 对列索引gender的值进行排列
```
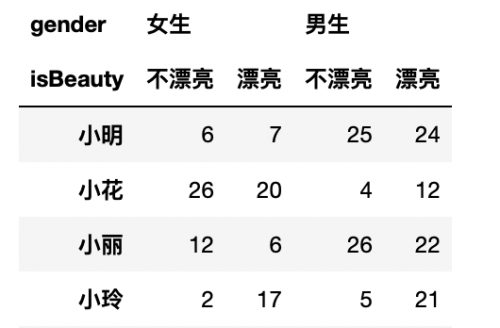
但是问题来啦!如果说按照男生的漂亮值降序排列如何实现?这就是多层索引的值排序啦!
```
df.sort_values(by=[('男生','漂亮')],ascending=False) # 注意观察参数by的内容
```
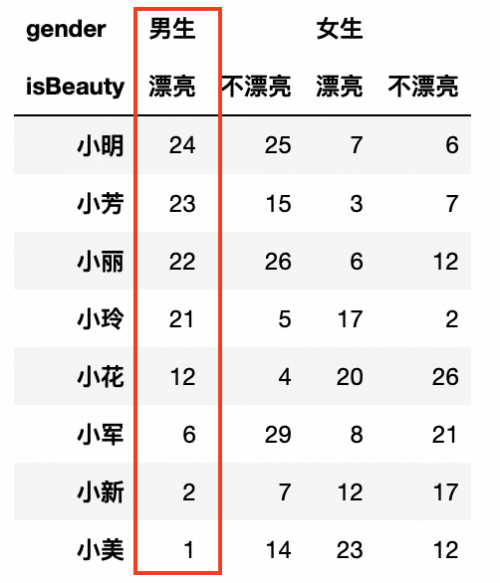
如果是按照女生不漂亮进行升序排列呢?
### 多级索引汇总统计
所谓汇总就是类似求和、求均值、最大值之类的。比如男生漂亮的最多票数是谁?男女生的漂亮数总和?
其实这个还是离不开我们常用的sum(),mean(),max(),min().....
```
df.sum(level=0,axis=1) # 男女生的票数总和,其中level指定了多层索引的索引值
```
或者
```
df.sum(level=1,axis=1) # 此时获取的就是漂亮和不漂亮的总和
```
结果:
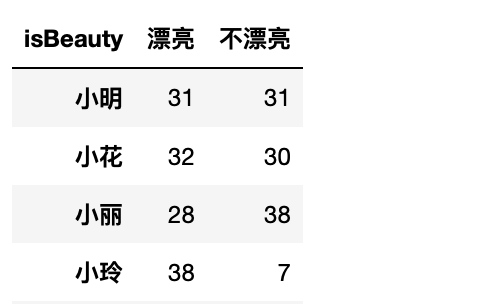
但是男生漂亮的最多票数是谁?这样就是跨行获取最大值
```
df.男生.漂亮.max()
```
所以很重要的就是:从求和这里我们来分析,就是我们是跨行求和还是跨列求和。跨行就是axis=0,跨列就是axis=1.
### 多级索引轴向转换
常见的数据层次化结构:树状和表格
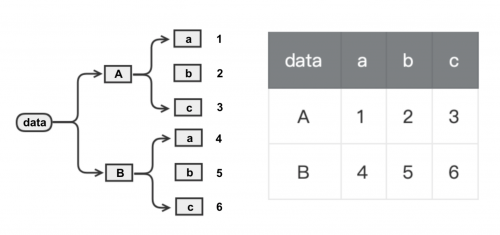
- 轴向转换的函数
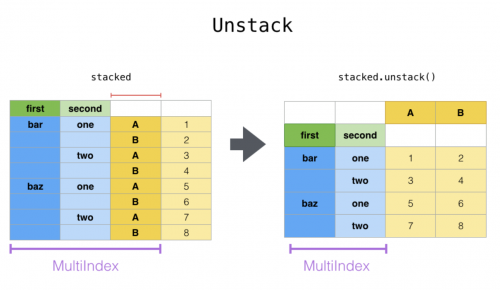
> 1. stack:“透视”某个级别的(可能是多层的)列标签,返回带有索引的 DataFrame,该索引带有一个新的最里面的行标签。
> 2. unstack:(堆栈的逆操作)将(可能是多层的)行索引的某个级别“透视”到列轴,从而生成具有新的最里面的列标签级别的重构的 DataFrame。
>
> stack 过程将数据集的列转行,unstack 过程为行转列。
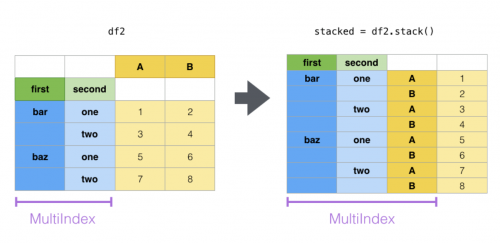
```
df1 = df.stack() # 默认是内层的进行转换
df1
```
截取部分:
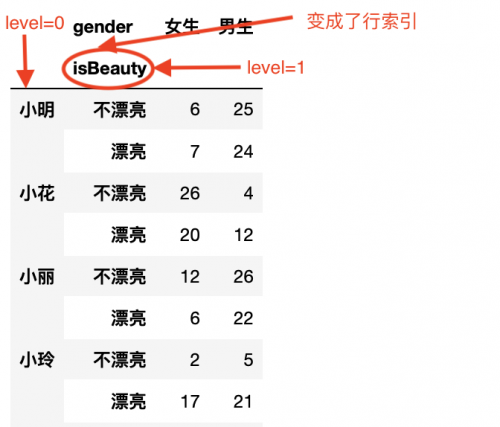
注意此时使用的是df1,df1是上图转换后的数据。按照上图标记的level=0和level=1
```
df1.unstack(level=0) # 就是将level=0的数据转换到列上
```
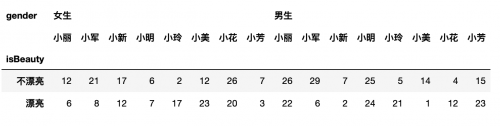
如果数据里面的缺失值,则可以使用dropna的参数即:df.stack(dropna=True)
另外还有一些属性,比如:
> df.index.names 查看行索引的名称
>
> df.columns.names 查看列索引的名称
>
> df.index.nlevels 层级数
>
> df.index.levels 行的层级
>
> df.columns.levels 列的层级
>
> df[['男生','女生']].index.levels 筛选后的层级
>
> df.index.droplevel(0) 删除指定等级
希望本篇文章可以给大家带来收获,如果喜欢的话,欢迎转发哦!















 京公网安备 11010802030320号
京公网安备 11010802030320号