


在进行大数据的面试过程中,经常会被问到一些比较相近的属性区别是什么,提前了解一下帮助你更好的应对面试提问。

1.repartition和coalesce的区别
1.1. repartition只是coalesce接口中shuffle为true的实现
1.2. 不经过 shuffle,也就是coaleasce shuffle为false,是无法增加RDD的分区数的,比如你源RDD 100个分区,想要变成200个分区,只能使用repartition,也就是coaleasce shuffle为true。
1.3. 如果上游为Partition个数为N,下游想要变成M个Partition
N > M , 比如N=100 M=60, 可以使用coaleasce shuffle为false。但是如果N远大于M,比如N=100, M=1, 分区有一个激烈的变化时,此时如果用coalesce就只有一个task处理数据,资源利用不够, Executor空跑,这时repartition是一个比较好的选择,虽然有shuffle但是和只有1个Task处理任务比起来效率还是较高。
N < M , coaleasce shuffle为false 不能增加分区,只能用repartition
2.groupByKey 和 reduceBykey 区别
reduceByKey 可以接收一个 func 函数作为参数,这个函数会作用到每个分区的数据上,即分区内部的数据先进行一轮计算,然后才进行 shuffle 将数据写入下游分区,再将这个函数作用到下游的分区上,这样做的目的是减少 shuffle 的数据量,减轻负担。
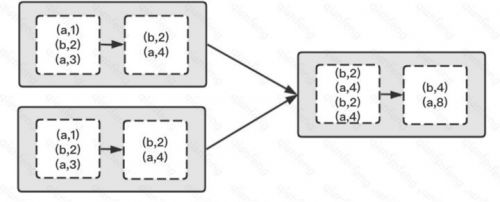
groupByKey 不接收函数,Shuffle 过程所有的数据都会参加,从上游拉去全量数据根据 Key 进行分组写入下游分区,这样会消耗比较多的资源,数据传输会导致任务处理的延迟。
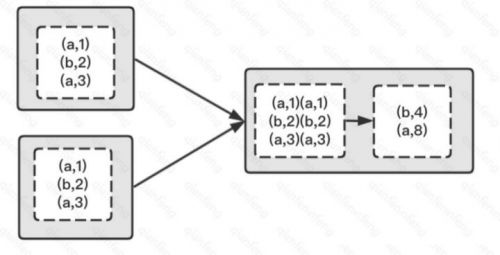
如果我们想要进行分组后进行聚合操作,使用 reduceByKey 会更高效, 因为reduceByKey 会在map阶段合并分区内相同的key,而gourpByKey 则不会合并。
3.Cache,Presist,CheckPoint的区别
Persist 的 MEMORY_ONLY 级别的存储等于 Cache,Persist 其他的配置只是存储的方式不同,作用和原理是和 Cache 类似的,他们二者的区别如下:
*Cache、Persist 是转化类算子,和其他算子一样,触发的时机是在对应分区的上游算子计算完成之后。
*Cache、Persist 会把 RDD 缓存到指定位置,这个操作不会改变 Lineage 血缘的依赖关系,且 Job 执行完成之后,缓存的数据会被清除。
*Cache、Persist 一般应用于需要访问重复数据的应用(如迭代型算法和交互式应用)缓存可以运行得更快。
*CheckPoint 执行完毕后,会产生 CheckPointRDD,此时 lineage 血缘关系已经改变了,容错会从CheckPointRDD 开始。
*CheckPoint 将 RDD 持久化到 HDFS ,会被永久保存,可以给其他的 Driver 使用
*虽然Presist 也可以持久化数据到磁盘,但是它有BlockManager管理,一旦Driver结束,BlockManager也会 stop,被 cache 到磁盘上的 RDD 也会被清空,而 checkpoint 将 RDD 持久化到HDFS或本地文件,如果不被手动 remove 掉,是一直存在的。
最后欢迎大家添加我们的大数据分享交流qq群:857910996 加群找管理领取免费的大数据学习资料,还可以交流学习心得,欢迎大家进群~~~















 京公网安备 11010802030320号
京公网安备 11010802030320号