


1.Flink的重启策略
答案:固定延迟重启策略(默认)
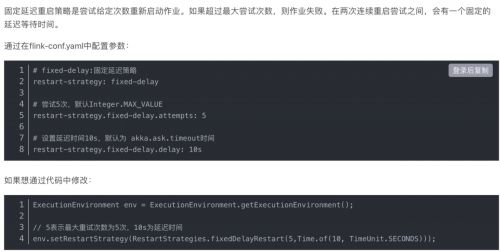
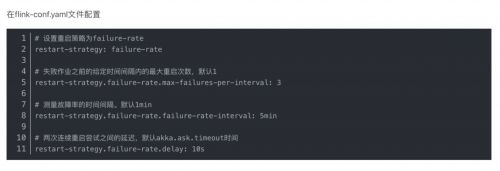
失败率重启策略
在一定时间内重启一定次数,超过这个次数则重启失败。
**代码设置:**
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 3为最大失败次数;5min为测量的故障时间;10s为2次间的延迟时间
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(5, TimeUnit.MINUTES),Time.of(10, TimeUnit.SECONDS)));
无重启策略
无重启,作业直接失败
2.checkpoint过程(Chandy-Lamport,分布式快照)
答案:
1)JobManager端的 CheckPointCoordinator向 所有SourceTask发送CheckPointTrigger,Source Task会在数据流中安插CheckPoint barrier
2)当task收到所有的barrier后,向自己的下游继续传递barrier,然后自身执行快照,并将自己的状态异步写入到持久化存储中。增量CheckPoint只是把最新的一部分更新写入到 外部存储;为了下游尽快做CheckPoint,所以会先发送barrier到下游,自身再同步进行快照
3)当task完成备份后,会将备份数据的地址(state handle)通知给JobManager的CheckPointCoordinator;如果CheckPoint的持续时长超过 了CheckPoint设定的超时时间,CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator就会认为本次CheckPoint失败,会把这次CheckPoint产生的所有 状态数据全部删除。
4)最后 CheckPoint Coordinator 会把整个 StateHandle 封装成 completed CheckPoint Meta,写入到hdfs。
3.什么是barrier对齐?
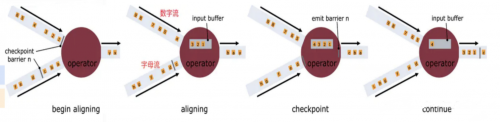
答案:一旦Operator从输入流接收到CheckPoint barrier n,它就不能处理来自该流的任何数据记录,直到它从其他所有输入接收到barrier n为止。否则,它会混合属于快照n的记录和属于快照n + 1的记录;
接收到barriern的流暂时被搁置。从这些流接收的记录不会被处理,而是放入输入缓冲区。
虽然数字流对应的barrier已经到达了,但是barrier之后的1、2、3这些数据只能放到buffer中,等待字母流的barrier到达;
一旦最后所有输入流都接收到barrier n,CheckPoint barrier n接着往下游发送,Operator就会把缓冲区中pending 的输出数据发出去
这里还会对自身进行快照;之后,Operator将继续处理来自所有输入流的记录,在处理来自流的记录之前先处理来自输入缓冲区的记录。
更多关于“大数据培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。















 京公网安备 11010802030320号
京公网安备 11010802030320号