


大数据经典面试题答疑---经常问的原理问题总结(系列文章,持续更新),帮你解决大数据开发中的困扰。
1. hive+MapReduce
答案区:
1.hbase
1.1. hbase基础
1.1.1. hbase数据模型
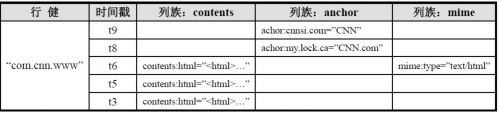
1.1.2. Row Key
概括:最大64KB;在hbase中以字节数组保存;不同rowkey按字典顺序排序
1.1.3. Columns Family
列簇 :HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。
1.1.4. Cell
由{row key, columnFamily, version} 唯一确定的单元。cell中 的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
1.1.5. Time Stamp
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。
一是保存数据的最后n个版本;
二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
1.2. 原理
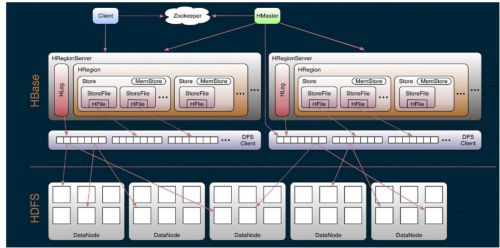
Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
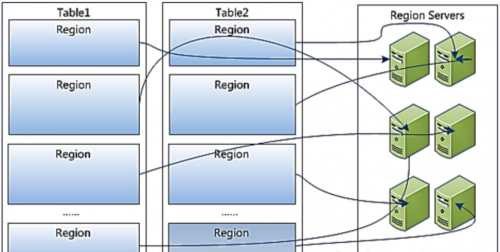
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。
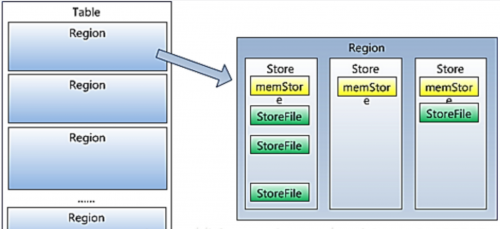
1.2.1. 写流程:
1、client向hregionserver发送写请求。
2、hregionserver将数据写到hlog(write ahead log)。为了数据的持久化和恢复。
3、hregionserver将数据写到内存(memstore)
4、反馈client写成功。
1.2.2. 数据flush:
1、当memstore数据达到阈值(默认是128M)或region中所有Memstore的大小总和达到了上限(默认 2*128 = 256MB)会触发将将数据刷到硬盘,将内存中的数据删除,同时删除Hlog中的历史数据。
2、并将数据存储到hdfs中。
3、在hlog中做标记点。
1.2.3. 数据compact(合并):
将storefile 中的hfile 合并成大的hfile;
在hbase中主要存在两种类型的compaction合并
minor compaction 小合并
在将Store中多个HFile合并为一个HFile,对于超过了TTL的数据、删除的数据仅仅只是做了标记。
major compaction 大合并
合并Store中所有的HFile为一个HFile,清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。默认7天执行一次,并且性能消耗非常大。手动触发:major_compact tableName
1.2.4. 读流程
1、通过zookeeper和-ROOT- .META.表定位region
2、hbase会首先在布隆过滤器中查询(如果设置的话),然后MemStore,BlockCache(LRUCache存放最近读取数据),磁盘的HFile,找到并存储到BlockCache
3、数据块会缓存
1.2.5. hregionserver的职责
HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
HRegion Server管理region。
1.3. hbase 布隆过滤器
不存在的一定不存在,存在的不一定存在;
1.3.1. 布隆过滤器的存储在哪?
对于hbase而言,当我们选择采用布隆过滤器之后,HBase会在生成StoreFile(HFile)时包含一份布隆过滤器结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。
cell较小的不适用布隆过滤器;
按行读,更新数据量大,范围广(多列),用row;
1.3.2. 协处理器
observe:通过钩子函数,做一些预处理和后处理;类似于 RDBMS 中的触发器,主要在服务端工作,主要有三种
regionObserve:处理数据修改数据;如:创建二级索引
maserObserve:管理DDL类型操作
WALObserve:提供针对WAL的钩子函数
endpoint:类似于 RDBMS 中的存储过程,主要在服务端工作,可以实现 min、max、avg、sum、distinct、group by 等功能。
更多关于大数据培训的问题,欢迎咨询千锋教育在线名师,如果想要了解我们的师资、课程、项目实操的话可以点击咨询课程顾问,获取试听资格来试听我们的课程,在线零距离接触千锋教育大咖名师,让你轻松从入门到精通。















 京公网安备 11010802030320号
京公网安备 11010802030320号