


大数据经典面试题答疑---经常问的原理问题总结(系列文章,持续更新),帮你解决大数据开发中的困扰。
1. yarn
答案区:
1. yarn
1.1 基础
1.1.1.hadoop 1.x
JobTracker,TaskTracker
缺点:JobTracker负载过重,存在单点故障;与MapReduce强耦合,其他计算框架需要重复实现资源管理;
1.1.2.hadoop 2.x
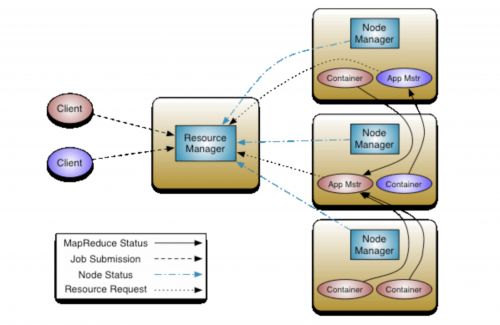

App Mstr (Application Master进程)
1.1.3.工作流程
如架构图所示,大致的工作流程如下:
1. 用户使用客户端向 RM 提交一个任务,同时指定提交到哪个队列和需要多少资源。用户可以通过每个计算引擎的对应参数设置,如果没有特别指定,则使用默认设置。
2. RM 在收到任务提交的请求后,先根据资源和队列是否满足要求选择一个 NM,通知它启动一个特殊的 container,称为 Application Master(App Mstr,AM),后续流程由它发起。
3. AM 向 RM 注册后根据自己任务的需要,向 RM 申请 container,包括数量、所需资源量、所在位置等因素。
4. 如果队列有足够资源,RM 会将 container 分配给有足够剩余资源的 NM,由 AM 通知 NM 启动 container。
5. container 启动后执行具体的任务,处理分给自己的数据。NM 除了负责启动 container,还负责监控它的资源使用状况以及是否失败退出等工作,如果 container 实际使用的内存超过申请时指定的内存,会将其杀死,保证其他 container 能正常运行。
6. 各个 container 向 AM 汇报自己的进度,都完成后,AM 向 RM 注销任务并退出,RM 通知 NM 杀死对应的 container,任务结束。
1.2. yarn有哪些调度
FIFO:单队列 先进先出 小任务易阻塞
CAPACITY:多队列 各队列资源固定 小任务可同时运行,可弹性使用资源

每个队列都可以设置最大值,不设置的话可用到整个父队列的资源最大值(正好有空闲时);
FAIR:多队列 各队列资源***\*动态抢占\**** 小任务可同时运行
队列创建时:除非队列被准确的定义,否则会以用户名为队列名创建队列
抢占就是允许调度器杀掉占用超过其应占份额资源队列的containers,这些containers资源便可被分配到应该享有这些份额资源的队列中。
默认调度器
Apache 开源:CAPACITY
CDH版本:FAIR
1.3. 常用命令
yarn logs -applicationId application_1539198654522_1073695 |more
1.查看 Job 信息:
hadoop job -list
2.杀掉 Job:
hadoop job –kill job_id
hadoop job –status job_id
更多关于大数据培训的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。















 京公网安备 11010802030320号
京公网安备 11010802030320号