


大数据经典面试题答疑---经常问的原理问题总结(系列文章,持续更新),帮你解决大数据开发中的困扰。
1. HDFS
答案区:
1.HDFS

1.1. 读数据

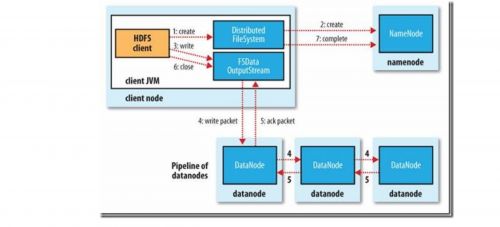
1.2.写数据
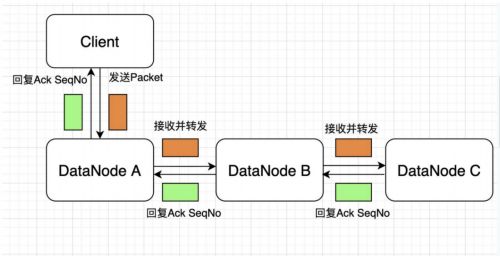

如果在写的过程中某个datanode发生错误,会采取以下几步:
1) pipeline被关闭掉;
2)为了防止防止丢包ack quene里的packet会同步到data quene里;
3)把产生错误的datanode上当前在写但未完成的block删掉;
4)block剩下的部分被写到剩下的两个正常的datanode中;
5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6.当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
校验
1.2.1. HDFS在写入过程中如何保证packet传输的一致性
hdfs写入的时候计算出校验和,然后每次读的时候再计算校验和。hdfs每固定长度就会计算一次校验和,这个值由io.bytes.per.checksum指定,默认是512字节。因为CRC32是32位即4个字节,这样校验和占用的空间就会少于原数据的1%。
datanode在存储收到的数据前会校验数据的校验和,比如收到客户端的数据或者其他副本传过来的数据。hdfs数据流中客户端写入数据到hdfs时的数据流,在管道的最后一个datanode会去检查这个校验和,如果发现错误,就会抛出ChecksumException到客户端。
可以在对FileSystem调用open()之前调用setVerifyChecksum()来禁止校验和检测.
也可以通过在shell中执行-get,-copyToLocal命令时指定-ignoreCrc选项做到.
1.3. namenode
根据元数据增长趋势,参考本文前述的内存空间占用预估方法,能够大体得到NameNode常驻内存大小,一般按照常驻内存占内存总量~60%调整JVM内存大小可基本满足需求。
为避免GC出现降级的问题,可将CMSInitiatingOccupancyFraction调整到~70。
NameNode重启过程中,尤其是DataNode进行BlockReport过程中,会创建大量临时对象,为避免其晋升到Old区导致频繁GC甚至诱发FGC,可适当调大Young区(-XX:NewRatio)到10~15。
据了解,针对NameNode的使用场景,使用CMS内存回收策略,将HotSpot JVM内存空间调整到180GB,可提供稳定服务。继续上调有可能对JVM内存管理能力带来挑战,尤其是内存回收方面,一旦发生FGC对应用是致命的。这里提到180GB大小并不是绝对值,能否在此基础上继续调大且能够稳定服务不在本文的讨论范围。结合前述的预估方法,当可用JVM内存达180GB时,可管理元数据总量达~700M,基本能够满足中小规模以下集群需求。
结论:
1)Total = 198 ∗ num(Directory + Files) + 176 ∗ num(blocks) + 2% ∗ size(JVM Memory Size)
2)受JVM可管理内存上限等物理因素,180G内存下,NameNode服务上限的元数据量约700M。
更多关于大数据培训的问题,欢迎咨询千锋教育在线名师。千锋教育拥有多年IT培训服务经验,采用全程面授高品质、高体验培养模式,拥有国内一体化教学管理及学员服务,助力更多学员实现高薪梦想。















 京公网安备 11010802030320号
京公网安备 11010802030320号