


在使用node开发后端项目的时候,通常会选择mongodb作为数据库,而使用mongodb通常是选择mongoose作为操作mongodb的驱动。
首先我们知道mongodb是非关系型的的数据库,也就是说保存的每行数据的字段都可以不一样、不统一,我们以一个简单博客系统的数据为例,涉及到的数据信息可能会有用户、文章、留言。
小明发一篇文章, 那么小明的数据如下:
```js
{
name:'小明',
articles:[
{
content:'这是一篇文章内容'
}
]
}
```
两篇文章:
```js
{
name:'小明',
articles:[
{
content:'这是一篇文章内容'
},
{
content:'这是第二篇文章的内容'
}
]
}
```
还有每篇文章都可能有留言的,例如小红给小明的文章留言,那么数据就会如下:
```js
{
name:'小明',
articles:[
{
content:'这是一篇文章内容',
msgs:[
{
name:'小红',
content:'小红给小明的留言'
}
]
},
{
content:'这是第二篇文章的内容',
msgs:[
{
name:'小红',
content:'小红给小明第二篇文章的留言'
}
]
}
]
}
```
小王也给小明的文章留言,那么数据如下:
```js
{
name:'小明',
articles:[
{
content:'这是一篇文章内容',
msgs:[
{
name:'小红',
content:'小红给小明的留言'
},
{
name:'小王',
content:'小王给小明的留言!!'
}
]
},
{
content:'这是第二篇文章的内容',
msgs:[
{
name:'小红',
content:'小红给小明第二篇文章的留言'
},
{
name:'小王',
content:'小王小明第二篇文章的留言!!'
}
]
}
]
}
```
问题来了,因为文章信息、留言信息都是保存在用户的信息下,如果某个用户的信息修改了,那么都需要遍历其他的用户的数据去做修改,如:小红的信息修改了,那么也需要去小明的文章下找到小红的信息去修改。 或者需要修改文章也需要通过用户的信息去修改。 这样就比较麻烦了,也不高效。
于是就有了数据库关系查询,mongodb也是最像关系型数据库的非关系型数据库,就是让他们的相同类别数据存在同一个集合(表)中, 让行内的某个字段做集合与集合之间的对应关系,通常是用id作为集合之间的映射关系。
我们直接使用mongoose操作mongodb:
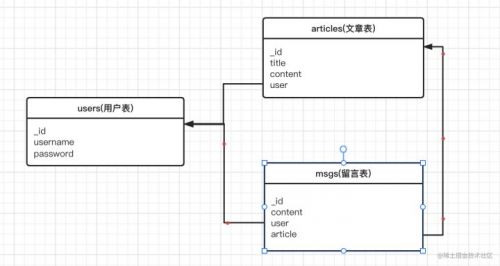
首先准备三个集合(表)
users 存放用户信息
articles 存放文章信息,每篇文章都属于某个用户(用user字段和users的_id字段做关联)
msgs : 存放留言信息,每条留言都属于某个用户,每条留言也属于某篇文章(用user字段和users的*id字段做关联, 用article字段和articles的*id做关联)
关系如下图:
对应的Scheme (_id字段在保存数据的时候会自动添加,所以我们不用定义)
userModel.js
```js
const mongoose = require('./db');
const schema = mongoose.Schema({
username:String,
password: String
},{collection:'users'})
const model = mongoose.model('users',schema)
module.exports = model;
```
articleModel.js
```js
const mongoose = require('./db');
const schema = mongoose.Schema({
title: String,
content: String,
user: {type: mongoose.Schema.Types.ObjectId, ref:'users'}
},{collection:'articles'})
const model = mongoose.model('articles',schema)
module.exports = model;
```
msgModel.js
```js
const mongoose = require('./db');
const schema = mongoose.Schema({
content: String,
user: {type: mongoose.Schema.Types.ObjectId, ref:'users'},
article: {type: mongoose.Schema.Types.ObjectId, ref:'articles'},
},{collection:'msgs'})
const model = mongoose.model('msgs',schema)
module.exports = model;
```
## 关联查询(一对一)
1.查询文章对应查询文章的用户信息
使用populate方法填充方法
参数1: 需要查询的关联字段
参数2: 关联查询出来的信息需要显示字段
```js
articleModel.find().populate('user','username avatar').exec(function(err,as){
console.log(as)
})
```
这样查询出来的文章信息都带有用户信息,而不是只有一个用户id
## 关联查询(一对多)
想要查询文章,然后查询出关于这篇的所有留言
### 1.聚合查询方式:
在这里的话,需要用到聚合查询,查询方式如下
```js
// 多集合关联查询
articleModel.aggregate([
{
$lookup:{
from:'msgs', // 关联的集合
localField:'_id', // 本地关联的字段
foreignField:'article', // 对方集合关联的字段
as:'mms', // 结果字段名,
},
}
],(err,dds)=>{
console.log(dds)
})
```
使用aggregate()方法就可以使用聚合查询了,方法接收一个数组参数
$lookup是关联查询的意思,就像SQL中的join
### 2.虚拟字段查询方式
在articleModel.js 中添加如下代码
```js
schema.virtual('mms',{ // 参数1为加的虚拟字段名称
ref:'msgs', //关联查询的集合
localField: '_id', // 当前集合和对方集合关联的字段
foreignField: 'article', // 对方集合字段和本集合关联的字段
count: true // count是否只显示总条数; true为显示, false为不显示
})
// 下面这两句只有加上了, 虚拟字段才可以显性的看到,不然只能隐性使用
schema.set('toObject',{virtuals:true})
schema.set('toJSON',{virtuals:true})
```
virtual 方法是给schema添加虚拟字段,
参数1 : 虚拟字段的名称
参数2: 虚拟字段的配置
然后通过populate查询
```js
articleModel.find().populate('mms').exec((err,as)=>{
console.log(as)
})
```
这样查询出来的文章列表就有个mms字段了,这个字段对应的这篇文章的留言总数
以上就是使用mongoose 做多集合关联查询的方法。
## 总结
一对一关系的集合可以通过populate填充查询。
一对多关系的集合可以通过聚合和虚拟字段进行查询
更多关于web培训的问题,欢迎咨询千锋教育在线名师。千锋教育拥有多年IT培训服务经验,采用全程面授高品质、高体验培养模式,拥有国内一体化教学管理及学员服务,助力更多学员实现高薪梦想。















 京公网安备 11010802030320号
京公网安备 11010802030320号