


一提到爬虫,大多数同学都想到的是Python,今天小千就给大家上一下不同的菜,利用js制作一个爬虫,Python用腻了来试试js吧。
一、引言
最近娱乐圈比较的火的算是郑爽事件了,作为一名程序猿如何能或者最新的娱乐热点新闻呢? 今天咱们就用js做一个网络爬虫,来爬取一个网站的新闻数据。
二、什么是爬虫?
网络爬虫,又称为网页蜘蛛,网络机器人,意思是我们通过程序去搜集网络上某些网站的数据。典型的通过爬虫获取数据的网站,比如百度、谷歌等搜索引擎。还有一些新闻聚合类网站,比如今日头条等网站。之前淘宝的一淘,返利网等网站都是利用了爬虫技术去获取别人网站的一些信息。 爬虫也不能乱用,无限制的去爬取一个网站的信息,那样会导致人家公司服务器压力比较大。之前有句爬虫界比较流行的话:爬虫玩的好,监狱进的早;数据玩的溜,牢饭吃个够!做技术的要有自己的底线,之前有程序员用爬虫为公司做了一些工作,结果公司被诉讼,程序猿被带走!
三、开始之前
为了防止出一些意外,首先我们可以访问你要爬取的目标网站的robots协议。 robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络爬虫:此网站中的哪些内容是不应被爬虫获取的,哪些是可以被爬虫获取的。参考robots.txt去爬取数据,再设置一下间歇时间,不会有人在意的。
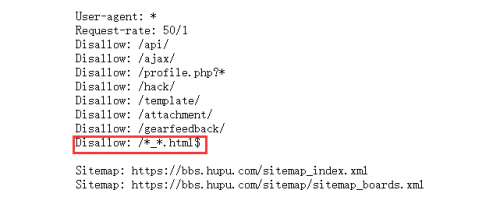
红色部分是关键,所有的网页都不能被爬取!!有句话不知当讲不当讲!

冷静下来,文章还没写就要结束了吗?我的kpi咋办!!!
看看我们的今天要爬取的网页地址,我们今天要爬取的网页后缀名不是html!!!
不知道是不是网站的技术人员忽略了这样的地址,哈哈哈。
四、正式开始
我们使用nodejs做爬虫,要使用到两个npm包,cheerio 和 axios
首先按照nodej,然后安装axios和cheerio 。
五、安装axios
axios是一个可以发起请求从而获取网页内的包。
键盘上按win+r,输入CMD,在里面输入 npm i aixos
就可以安装axios
六、安装cheerio
安装cheerio cheerio 是一的用法跟jQuery的用法差不多。 就是先将页面的数据load进来形成一个特定的数据格式,然后通过类似jq的语法,对数据进行解析处理。 终端中输入
npm i cheerio
七、爬取数据
新建sp.js文件,写入如下代码
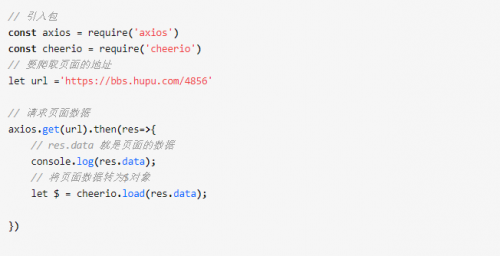
执行node sp.js 命令
网页的数据已经获取到了,然后我们就可以使用jquery的语法获取页面中的数据了。 下面我们分析一下页面的结构
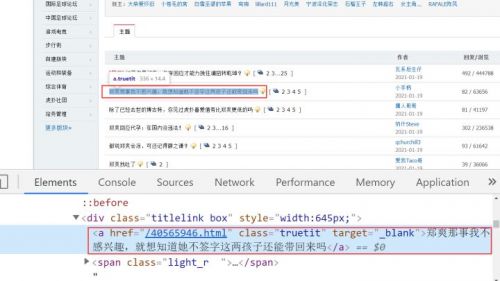
可以看到页面中所有的新闻标题都在a标签中,类名是truetit。然后我们就可以使用jq的选择器获取页面中所有类名为truetit的元素。

终端中结果

这样每次执行就可以获取最新的娱乐新闻,不需要打开网页就可以获取到,当然我们只是获取了第一页的数据,你也可以获取第二页、第三页等其他页面的数据。 我们现在相当于只获取了一个网站的娱乐数据,如果你再分析一些其他的网站,获取一些其他的网站的数据,然后把数据都存储起来,自己就可以做一个只显示娱乐新闻的网站了!
学习web前端,可以参考千锋web前端培训班提供的web前端学习路线,该学习路线对从零基础小白到web前端初级开发工程师,web前端高级开发工程师,后面的web前端大神级开发工程师都有一个明确清晰的指导,根据千锋web前端培训机构提供的web前端学习路线图可以让你对学习web前端开发需要掌握的知识有个清晰的了解,并快速入门web前端开发。想要获取前端完整学习路线和免费的学习资料可以添加我们的web前端技术分享交流qq群:857920838 加群找群管理领取即可,等你来哦~~















 京公网安备 11010802030320号
京公网安备 11010802030320号