


一、Linux可执行文件结构
在 Linux 下,程序是一个普通的可执行文件,以下列出一个二进制可执行文件的基本情况:

可以看出,此可执行文件在存储时(没有调入到内容)分为代码区(text)、数据区(data)和未初始化数据区(bss)3 个部分。各段基本内容说明如下:
代码区:
存放 CPU 执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。另外,代码区还规划了局部变量的相关信息。
代码区的指令包括操作码和操作对象(或对象地址引用)。如果是立即数(即是具体的数值),将直接包含在代码中,如果是局部数据,将在运行时在栈区分配空间,然后再引用该数据的地址,如果是未初始化数据区和数据区,在代码中同样将引用该数据的地址。
全局初始化数据区/静态数据区(数据段):
该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。
例如,一个不在任何函数内声明(全局变量),如下:
int count = 100;
使得变量 count 根据其初始值被存储初始化数据区中。
在任意位置定义静态变量方式如下:
static int num = 200;
这声明了一个静态数据并初始化,如果在任意函数体外声明,则表示其为一个静态全局变量,如果在函数体内(局部),则表示其为一个局部静态变量。另外,如果在一个函数名前加上 static,则表示此函数只能再当前文件中被调用。
未初始化数据区(又叫 BSS 区):
存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为 0 或者空(NULL)。
例如,一个不在任何函数内声明的未初始化变量。
long sum[1000];
将 sum 存储到未初始化数据
二、Linux进程结构
在 Linux 系统下,如果将某个可执行文件加载到内存运行,则将演变成一个或多个进程(多个进程的原因是进程在运行时可以再创建新的进程,但加载时只有一个进程)。进程是 Linux 事务管理的基本单元,所有的进程均拥有自己独立的处理环境和系统资源。进程的环境由当前系统状态及其父进程信息决定和组成的。
下图为可执行文件存储结构和 Linux 进程基本结构(部分)的对照图。
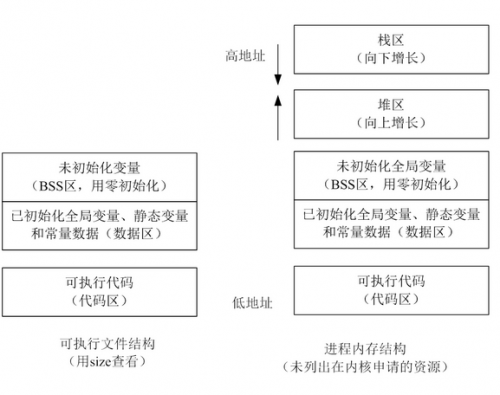
一个进程是一个运行着的程序段,一个进程主要包括在内存中申请的空间,代码(加载的程序,包括代码段,数据段,BSS),堆,栈,以及内核提供的内核进程信息结构体task_struct (位置在 /usr/include/linux/sched.h)、打开的文件、上下文(指进程执行活动全过程的静态描述)信息以及挂起的信号等。
(1)代码区(text segment)。加载的是可执行文件代码段,其加载到内存中的位置由加载器完成。
(2)全局初始化数据区/静态数据区(Data Segment)。加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据)的数据的生存周期为整个程序运行过程。
(3)未初始化数据区(BSS)。加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)的生存周期为整个程序运行过程。
(4)栈区(stack)。由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
(5)堆区(heap)。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
系统之所以分成这么多个区域,主要基于以下考虑:
代码段和数据段分开,运行时便于分开加载,在哈佛体系结构的处理器将取得更好得流水线效率。
代码时依次执行的,是由处理器 PC 指针依次读入,而且代码可以被多个程序共享,数据在整个运行过程中有可能多次被调用,如果将代码和数据混合在一起将造成空间的浪费。
临时数据以及需要再次使用的代码在运行时放入栈中,生命周期短,便于提高资源利用率。
堆区可以由程序员分配和释放,以便用户自由分配,提高程序的灵活性。
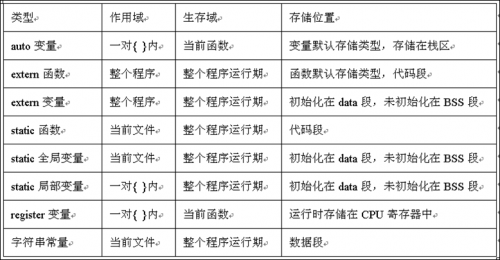
三、各存储类型比较















 京公网安备 11010802030320号
京公网安备 11010802030320号