


**Python norm函数:规范化数据的利器**

Python是一种简单易学的编程语言,拥有丰富的库和函数,能够帮助开发者高效地完成各种任务。其中,norm函数是Python中一个非常有用的函数,它可以帮助我们规范化数据,使其符合特定的标准或要求。
**什么是规范化?**
在数据处理和分析中,规范化是一种常见的操作,它可以将数据转化为统一的格式,以便更好地进行比较和分析。规范化可以应用于各种数据类型,包括数字、文本、日期等。通过规范化数据,我们可以消除数据间的差异,提高数据的可比性和可解释性。
**为什么需要规范化?**
在现实生活和工作中,我们常常会面临各种各样的数据,这些数据可能来自不同的来源、不同的格式,甚至可能存在一些错误或异常值。如果不对这些数据进行规范化处理,我们将很难对其进行有效的比较和分析。
例如,在一个销售数据表中,不同销售人员可能使用不同的单位表示销售额,有的使用万元,有的使用元,这样就会导致数据的不一致性。如果我们想要计算各个销售人员的销售额总和,就需要先将数据规范化为统一的单位,才能进行准确的计算。
**Python norm函数的基本用法**
在Python中,norm函数是一个非常方便的数据规范化函数,它可以帮助我们快速、准确地对数据进行规范化处理。norm函数的基本用法如下:
`python
norm(data, method='min-max', axis=0)
`
- data:需要进行规范化处理的数据,可以是一个数组、列表或DataFrame。
- method:规范化方法,可以是'min-max'、'z-score'或'log'中的一个,默认为'min-max'。
- axis:规范化的轴,可以是0或1,默认为0。
norm函数的返回值是经过规范化处理后的数据。
**常用的规范化方法**
1. 最小-最大规范化(min-max normalization):将数据线性映射到[0, 1]的区间内,公式如下:
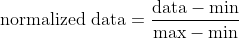
这种方法适用于数据的分布比较均匀的情况。
2. Z-Score规范化(z-score normalization):将数据转化为均值为0、标准差为1的正态分布,公式如下:

这种方法适用于数据的分布比较偏态的情况。
3. 对数规范化(log normalization):将数据取对数,可以有效地处理数据的偏态分布情况。
**常见的问答**
1. 问:如何选择合适的规范化方法?
答:选择合适的规范化方法需要根据数据的分布情况来决定。如果数据的分布比较均匀,可以选择最小-最大规范化;如果数据的分布比较偏态,可以选择Z-Score规范化;如果数据的分布呈指数增长或衰减的趋势,可以选择对数规范化。
2. 问:norm函数是否支持处理缺失值?
答:norm函数默认会忽略缺失值,即在进行规范化处理时会自动跳过缺失值。如果需要处理缺失值,可以在调用norm函数之前使用其他函数,如fillna()函数,对缺失值进行填充。
3. 问:norm函数是否支持处理多维数据?
答:是的,norm函数支持处理多维数据。在调用norm函数时,可以通过设置axis参数来指定规范化的轴,axis=0表示按列进行规范化,axis=1表示按行进行规范化。
**总结**
Python norm函数是一个非常实用的数据规范化函数,它可以帮助我们快速、准确地对数据进行规范化处理。通过规范化数据,我们可以消除数据间的差异,提高数据的可比性和可解释性。在选择规范化方法时,需要根据数据的分布情况来决定。norm函数支持处理缺失值和多维数据,具有很高的灵活性和适用性。无论是数据分析、机器学习还是其他领域的数据处理,norm函数都是一个不可或缺的利器。















 京公网安备 11010802030320号
京公网安备 11010802030320号