


001-OCR光学文字识别
一、OCR简介
OCR(Optical Character Recognition,光学文字识别)是指电子设备检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
各种场景都有OCR的身影,我们可以在任何地方使用到OCR。Python中常见的OCR有EasyOCR、PaddleOCR等,接下来我们以EasyOCR为例,演示其如何使用。
二、EasyOCR使用
EasyOCR是一个免费开源的OCR模块,其有自己的一系列的训练好的模型,借助这些模型,我们就可以识别各种场景下的文字。
Github链接:https://github.com/JaidedAI/EasyOCR
EasyOCR官网:https://www.jaided.ai/easyocr/
首先我们先来安装OCR:
Windows:pip install easyocr;Mac/Linux:pip3 install easyocr
安装完成以后
我们直接写代码即可
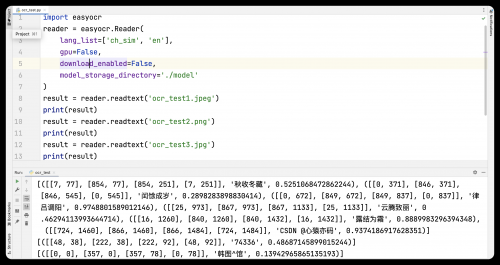
1.导入easyocr模块
import easyocr2.实例化Reader类
Reader类中有几个参数我们需要手动修改
lang_list:告诉它我们要识别的语言,以列表的形式传参,可以一次传递多种语言,但并非所有语言都可以一起使用,截止到2022年12月19日,已经支持80+种语言。这是目前支持的语言的链接:https://www.jaided.ai/easyocr/。我们这里写的ch_sim是简体中文,en是英文。
gpu:会让你选择使用cpu驱动还是gpu驱动,使用gpu驱动识别速度会更快一些,但是所要配置的环境也更复杂,如果有兴趣,可以自行研究一下,这里我们就使用cpu,将gpu改为False。
download_enabled:easyocr第一次运行时会先在线下载模型数据,但是鉴于网络不好,大部分人下载时都会发生错误,所以将download_enabled改为False,我们手动去下载模型数据。
model_storage_directory:这个参数是指定模型数据的引用路径,默认情况下在Windows系统中存放在C:\Users\用户名\.EasyOCR\model中,在Mac/Linux系统中存放在~/.EasyOCR/model中,我们可以通过修改model_storage_directory参数自行指定模型数据的路径,我这里就直接指定相对路径为./model。
注意:
除此之外还有很多其他参数,详情请见源码。
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'],
gpu=False,
download_enabled=False,
model_storage_directory='./model'
)
1.调用readtext方法
实例化Reader类以后,调用readtext方法读取图片。
readtext方法中有一个参数叫做image,把图片传给它即可。image参数可以接收图片路径、图片的numpy数组或者图片的字节流对象。一般情况下我们直接传递图片路径即可,除非有要求要针对图片做一些特殊处理。
result = reader.readtext(image='图片')
print(result)三、模型下载
刚刚我们说将download_enabled参数改为False,要去手动下载模型数据,这是模型数据下载地址:https://www.jaided.ai/easyocr/modelhub/。
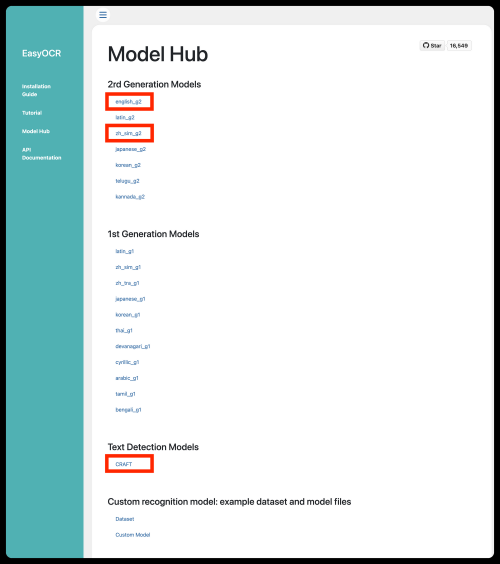
下载图中框选中的三个即可,下载下来为zip压缩包,一定要解压缩,我们需要的是其中的后缀名为pth的文件,并将其移动到我们自己创建的**model**文件夹中。因为我们要做文字识别就一定要有CRAFT,我们识别的大部分为简体中文和英文,所以下载zh_sim_g2和english_g2。当然,如果你要识别其他语言,请再次找其他语言的模型数据。
四、图片
在此提供几张图片,供大家测试。

按照官方的说法,准确率在90%以上,但是碰到识别不出来或者识别错误的概率还是蛮大的。















 京公网安备 11010802030320号
京公网安备 11010802030320号