


一. 问题复现
在上一篇文章中,小编分享了以前在工作中遇到的线上业务BUG解决思路,今天我会结合自己的授信中心这个金融项目,继续给大家分析如何对自己遇到的故障进行定位与解决,希望本文可以对缺乏实际开发经验的小白有所帮助。

其实要想解决开发故障,通常的解决思路大致如下:
1.分析问题,根据理论知识+经验分析问题所在,并将错误锁定在一定的范围内;
2.通过错误日志,快速定位问题。线上定位问题时,主要是依靠监控和日志。
比如小编遇到过这样一个问题:
线上的金融项目启动后,运行速度越来越慢,一段时间后直接无法访问,但此时的内存使用率正常,而CPU使用率几乎满负荷。在重启项目后,又运行了一段时间,项目重复出现该问题。
二. 解决思路
对于这种线上的故障,我们该怎么解决呢?其解决思路可以按照以下几个步骤来实现。
其实,大多数情况下,只要出问题,我们都可以利用 df(查看磁盘)、free(查看内存)、top(查看CPU) 来个素质三连,然后再通过jstack(Java堆栈跟踪工具)、jmap(Java堆和方法区的详细信息)等工具排查。这些工具的具体使用命令,大家可以自行查阅。
1.top命令
top命令或者其他监控数据,用于查看服务器的内存、cpu的使用情况。
2.jps命令
查看当前java程序的进程号,假如为:17357,
3.jstat命令
jstat -gc 17357 2000,可以查看jvm的内存分配情况,如图:

接着我们再通过查看EU和OU、YGC、FGC的变化,来调整jvm的内存、young区(edge,s1,s2)、old区内存大小。
可靠建议:
修改JAVA_OPTS='-Xms1024m -Xmx1024m' ,将jvm的最大、最小内存设为系统内存的3/4。根据ygc,调整young区中s与edge比例,根据fgc的频率调整young区和old区的大小(或比例)。
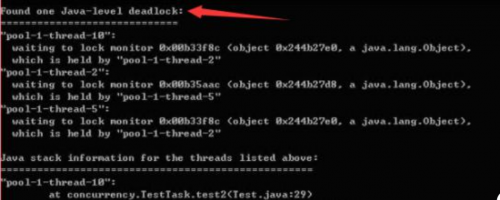
然后通过jstack 进程id,来查看线程的死锁,例如: jstack -l 21733 | more,若出现下图所示,则是出现了线程死锁。
1.tomcat优化
我们也可以在yml文件中tomcat的配置进行优化。
server:
port: 9105
tomcat:
threads:
处理请求的最大线程数
max: 350
最小的工作线程数
min-spare: 100
等待队列的最大队列长度
accept-count: 500
2.设置数据库连接池
对于数据库服务(如mysql),dba在部署的时候,都会设置db的最大内存和最大链接数,开发人员可以暂时忽略。
另外,数据库连接池请尽量别用dbch、c3p0等已经过时的连接池技术,推荐使用阿里巴巴的druid,其相关的链接配置,请参照其github的官网。
三. 具体解决过程
结合以上解决思路,接下来百泽给大家说一下我的具体解决过程。
1.top定位
由于cpu满负荷,所以我先通过top定位到出现问题的线程。发现确实是我们的java项目所在进程吃掉了所有的cpu资源,这时可通过jps+jstat来查看java的gc状态,进一步发现young gc几乎是一秒一次,fullgc没有。所以接着我又查看了jvm的设置,young内存才设为512m,我先去掉了这个配置,而是采用默认配置(young:old =1:2)。
在重启项目之后,young gc基本到了10多秒一次,可项目运行一段时间还是会卡死。然后我又看了下tomcat的连接池,发现全部都是默认配置(默认最大连接数为50),故先将最大链接设为500,等待队列设为1000,重启项目,还是出现cpu满负荷,系统卡死。
2.排查数据库服务的内存
接着我查看了输出的最新日志文件,发现日志输出到一个dao方法之后,在输出响应的sql后就卡住了。接着我通过mysql链接工具直接执行,sql却很快输出,因此排除数据库服务的内存不足等硬件问题。
3.调整日志输出级别
通过查看项目的框架,发现日志用的log4j(同步日志输出),日志输出级别是:INFO,这会导致项目里面的log输出非常多,所以我先将log的输出级别设为warn,重新启动项目,项目正常运行。
4.优化数据表
修改日志输出级别为warn之后,运行了一段时间发现系统又卡死了。这时还是两个表的查询卡死(通讯录和通话记录),这两个表的存储量级都是上亿级别的,项目原有的逻辑是这样的,用户上传通讯录,需要删除原来的通讯录,再批量插入。这样一个大表频繁的进行删除与批量插入,很容易导致IO响应慢。第一步,我先通过建立唯一索引,利用insert ignore into来减少该表的IO操作,接着重新启动项目,系统正常运行。
5.添加索引
加好索引优化了sql语句之后,系统还是偶尔会出现卡死状态。这时,我通过dba搜索慢查询,发现通话记录和通讯录表中有一个排序查询,该sql的末尾使用了order by update_time desc,但update_time没有添加索引,这就导致该表的查询至少要2秒以上。所以我将sql改为了order by id,查询就正常了,重启项目,系统正常运行。
6.解决线程死锁
至此,系统还是偶尔出现卡死现象(cpu爆表),只是频率小了很多。这时我怀疑是有线程死锁了,从而导致cpu爆表。我通过运维查找linux线程,终于发现确实有一个线程出现了死锁,里面的信息显示是c3p0的连接池线程。我又通过查找资料,发现使用c3p0作为数据库连接池,经常会出现链接池卡死的问题,所以我赶紧将项目的连接池切换为durid,然后重启项目,项目运行正常。

7.新增服务器节点
但系统在进件量较大时,依然有一定的几率出现卡死现象,最好考虑是当时的项目环境采用的是单机部署,所以最后协调运维新增了两个服务器节点,至此项目运行完全正常。
四. 总结
针对线上服务器故障的解决思路和过程,小编给大家提供了以下几个可靠建议:
1.系统框架太过于老旧时,可能会引发一系列的项目问题,所以适当升级项目的技术是有必要的。
2.一些大表一定要进行拆分,否则在高并发的环境中,数据库的IO会遇到瓶颈。
3.减少一些不必要的日志输出,日志输出组件尽量是异步输出的。
4.一些高频率查询的字段,尽量加上索引、组合索引,一些慢查询的sql优化也很重要。
5.服务尽量单独部署。















 京公网安备 11010802030320号
京公网安备 11010802030320号