


DQL是数据查询语言(Data Query Language)的缩写,是一种用于从数据库中检索数据的编程语言。DQL是SQL(结构化查询语言)的子集,用于查询关系型数据库,例如MySQL、Oracle和SQL Server等。
DQL提供了多种查询操作,如SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等。使用这些操作,可以根据特定的条件检索所需的数据,并按照特定的顺序进行排序和分组。
DQL还支持多表查询和子查询,可以从多个表中联合检索数据,并在子查询中使用嵌套查询语句进行检索。
基础的查询语法
select ... from ...select [distinct] ... from ... [where ...] [group by ...] [having ...] [order by ...] [limit ...]
查询语句的执行顺序
先执行from子句: 基于表进行查询操作
再执行where子句: 进行条件筛选或者条件过滤
再执行group by子句: 对剩下的数据进行分组查询。
再执行having子句: 分组后,再次条件筛选或过滤
然后执行select子句: 目的是选择业务需求的字段进行显示
再执行order by子句: 对选择后的字段进行排序
最后执行limit子句: 进行分页查询,或者是查询前n条记录
准备数据
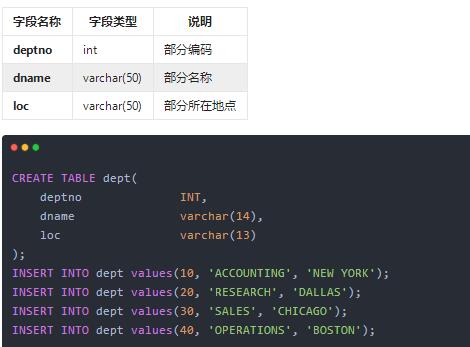
在学习接下来的查询的语法之前,我们提前准备几张表,并向这张表中插入一些数据,方便我们之后的查询操作。
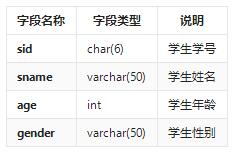
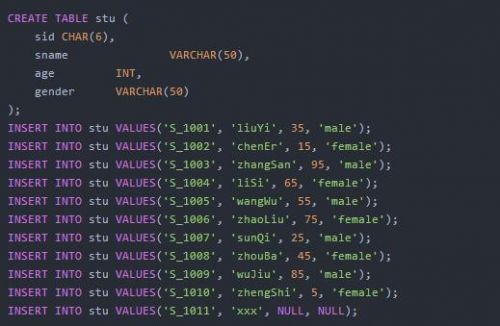
student表
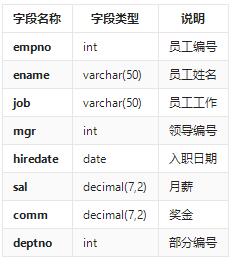
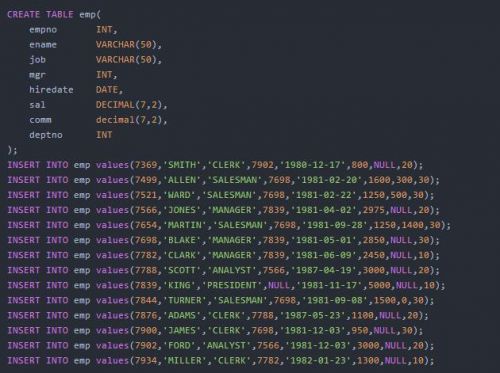
emp表
dept表
基础查询
1.查询所有列

2.查询指定列

条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
=、!=、<>、<、<=、>、>=、BETWEEN…AND、IN(set)、IS NULL、AND、OR、NOT、XOR (逻辑异或)
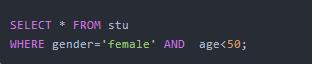
1.查询性别为女,并且年龄小于50的记录
2.查询学号为S_1001,或者姓名为liSi的记录

3.查询学号为S_1001,S_1002,S_1003的记录

模糊查询
按照模糊的条件进行查询,可以使用LIKE条件,或者REGEXP。
like
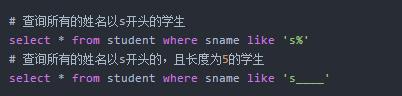
like用于where子句之后,表示部分的匹配。在like后,通常会有两种通配符:
_ => 表示匹配任意的一位字符。
% => 表示匹配任意位的字符。
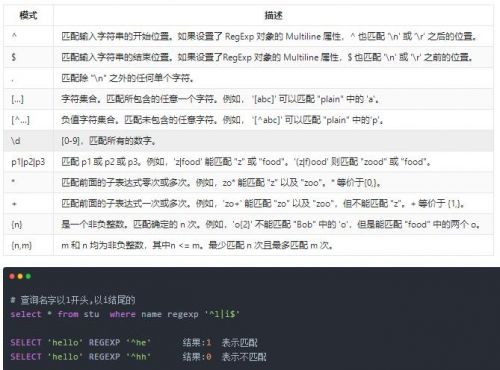
regexp
使用正则表达式进行字符串的匹配。
字段控制
去除重复记录
去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如emp表中sal字段就存在相同的记录。当只查询emp表的sal字段时,那么会出现重复记录,那么想去除重复记录,需要使用DISTINCT:

列之间的计算
查看雇员的月薪与佣金之和,因为sal和comm两列的类型都是数值类型,所以可以做加运算。如果sal或comm中有一个字段不是数值类型,那么会出错。

comm列有很多记录的值为NULL,因为任何东西与NULL相加结果还是NULL,所以结算结果可能会出现NULL。下面使用了把NULL转换成数值0的函数IFNULL

给列名添加别名
在上面查询中出现列名为sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为total:

给列起别名时,是可以省略AS关键字的:

结果排序
1.查询所有学生记录,按年龄升序排序
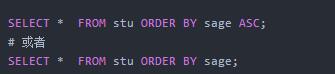
2.查询所有学生记录,按年龄降序排序

3.查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序

聚合函数
聚合函数,是作用在一列数据上的,对一列的数据进行运算的函数。包含有: max、min、sum、count、avg等常见的函数。
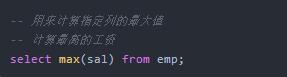
max(): 计算指定列数据的最大值
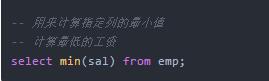
min(): 计算指定列数据的最小值
count(): 计算指定列不为NULL的数据的数量
sum(): 计算指定列的数值的和,如果计算的列的类型不是数值类型,计算结果为0
avg(): 计算指定列的数值的平均值,如果计算的列的类型不是数值类型,计算的结果为0
使用方法如下:
max
min
count

sum

avg

注意:
在上述的需求中,我们需要统计员工的平均工资。但是,有些行的数据中,工资(sal)对应的值是NULL。
例如: 表中一共有20行数据,有2行数据是NULL。那么平均值在计算的时候,会将每一个人的工资加到一起,用这个和除18,而并不是20。因为聚合函数不会统计NULL值的。
如果需求需要将这个和均摊到每一个人的身上,包括NULL的行,那就需要对这条SQL语句进行修改了:
select avg(ifnull(sal, 0)) from emp;
分组查询
在进行查询的时候,可以按照某一个或多个字段进行分组。分组字段值相同的行会被视为一个分组。一般情况下,分组的意义是对每一个分组的数据进行聚合的统计,例如统计每一个分组的数量、最大值等操作。
注意事项: 查询的字段中只能包含分组字段和聚合函数
group by
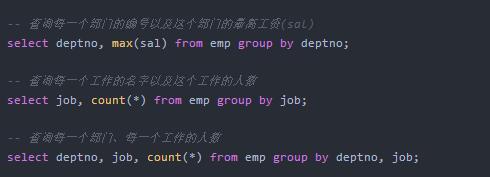
having
having是一个数据过滤的控制条件,类似于where,但是又和where有不同的地方:
having是作用在分组之后的数据的,where是作用在分组之前的数据的。被where过滤掉的数据不参与分组。
写法体现: having需要写在group by之后,where需要写在group by之前。
having之后可以使用聚合函数,where不可以使用聚合函数。

imit
select查询语句会查询出来一张表中所有的满足条件的数据。limit关键字可以限制查询结果的行数。
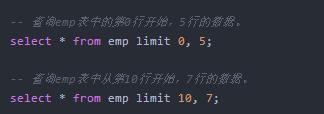
灵活的使用limit,可以实现分页查询的效果。

查询总结
查询语句书写顺序
select – from - where - group by - having - order by - limit
查询语句执行顺序
from - where -group by - having - select - order by-limit















 京公网安备 11010802030320号
京公网安备 11010802030320号