


现在越来越多的人喜欢化妆、医美啊,所以长得都一样。放眼望去大街上到处是美女,而且怎么还长得很像呢?
我们测测他们的颜值如何吧? 此次我们明星里的美女帅哥为例测试颜值(当然也可以加入你的照片了,只要结果不怕被打击)
测评步骤:
爬取贴吧中的你想测评的明星美女和帅哥们
使用第三方的人脸识别测评工具
使用数据分析对其结果进行可视化
先给大家一个效果图,帅哥的颜值排名!
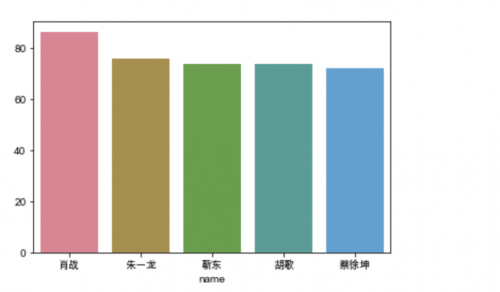
想知道你的颜值吗?那我们就开始吧!
爬虫部分
此次我们爬取的是百度贴吧中的明星图片,以刘诗诗的图片爬取为例
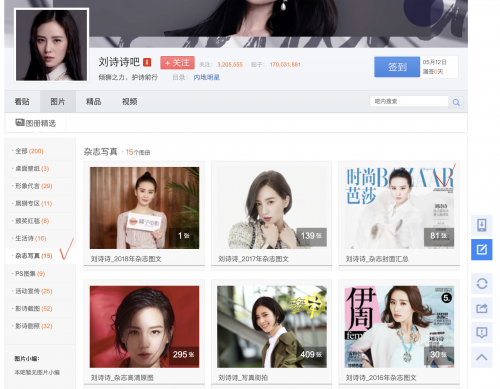
链接:https://tieba.baidu.com/p/3263751314#!/l/p1
分析一下图片的加载方式,发现是AJAX的异步请求,请求的链接是:

其中红线位置的是有变化的部分。pn=1表示第一页的图片显示,除了默认加载的图片随着鼠标的滑动在第一页还可以加载更多的内容,但是需要指定开始和结束位置。而ps=1就表示从第1开始,pe=40就表示到40结束(ps和pe中的s表示start,e表示end)。一页一共有200条数据,那后面的红线位置是什么呢?是不断变化的数值。通过分析我们了解到这个数值是时间戳。于是我们可以这样拼接我们的请求链接。
import time
def get_timestamp():
t = str(time.time())
return t.replace(".","")[:-3] # 因为最后的时间是13位
if __name__ == '__main__':
for page in range(1,2):
for i in range(page,page+5):
start = (i-page)*40+1+200*(page-1)
end = 200*(page-1)+(i-page+1)*40
ts = get_timestamp()
url = f'https://tieba.baidu.com/photo/g/bw/picture/list?kw=%E5%88%98%E8%AF%97%E8%AF%97&alt=jview&rn=200&tid=3263751314&pn={page}&ps={start}&pe={end}&info=1&_={ts}'
print(url)
OK!这样我们的链接就做好了,注意本次选择的只有一页。所以外层循环是range(1,2)。
因为这个链接返回结果是Json数据,所以我们网络请求要这样处理
head = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36",
'Referer': 'https://tieba.baidu.com/p/1457326101'} # 必不可少的Referer 认证
# 通过requests获取访问的页面
def get_json(url):
r = requests.get(url, headers=head)
if r.status_code != 200: # 如果没有正常获得网页,产生异常
raise Exception()
return r.json()
这样我们就可以获取所有图片的json数据啦!但是我们要从数据中把图片的链接解析出来。格式化后的json如下图:
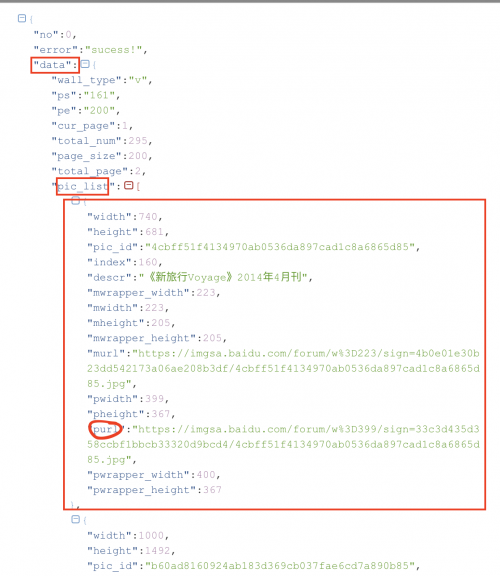
我们现在要从json中把purl对应的链接解析出来,代码如下
def parse_json(json, name):
pic_list = json.get('data').get('pic_list')
for pic in pic_list:
purl = pic.get('purl')
# time.sleep(3) # 此处可以考虑使用休眠
拿到purl之后,我们可以再次请求网络进行下载
head1 = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36",
'Host': 'imgsrc.baidu.com'
}
def get_pic(pic_url, name):
r = requests.get(pic_url, headers=head1)
if r.status_code != 200: # 如果没有正常获得网页,产生异常
raise Exception()
filename = pic_url.rsplit('/')[-1]
print(filename)
with open('girl1/' + name + filename, mode='wb') as sw:
sw.write(r.content)
print('下载图片:' + filename + '成功!')
这样图片就会被保存到指定的位置,注意在保存的时候使用了一个name,主要用于后期我们进行识别时的分类。
最后在入口调用上面的函数代码如下:
def maindown(url, name):
num = 1
# 下载html页面
json = get_json(url)
# 从页面中提取链接
parse_json(json, name)
if __name__ == '__main__':
for page in range(1, 5):
for i in range(page, page + 5):
start = (i - page) * 40 + 1 + 200 * (page - 1) # 201. 241. 281. 321 361
end = 200 * (page - 1) + (i - page + 1) * 40 # 240 280 320 360 400 440. 3*40
ts = get_timestamp()
url = f'https://tieba.baidu.com/photo/g/bw/picture/list?kw=%E5%88%98%E8%AF%97%E8%AF%97&alt=jview&rn=200&tid=3263751314&pn={page}&ps={start}&pe={end}&info=1&_={ts}'
# 下载html页面
json = get_json(url)
# 从页面中提取图片链接并下载到本地
parse_json(json, name)
time.sleep(5) # 此处加了休眠的目的是防止被阻止爬取
下载成功后的图片展示:

颜值测评
颜值测评我们使用到的是百度的AI人脸检测,我们并没有使用自定义的人脸检测部分。
所以我们要简单的了解下如何使用人家做好的现成的东西,当然这个不仅仅可以测颜值,还可以测年龄,性别啊等等。可以参考官方文档:http://ai.baidu.com/ai-doc/FACE/yk37c1u4t
要想使用人脸检测这款产品首先要注册成为百度账户才可以。步骤是:
成为开发者
创建应用
获取密钥,进入应用中获取密钥
生成签名,这个要依赖你上面创建应用的AppID、API Key及Secret Key三个值,进行Access Token(用户身份验证和授权的凭证)的生成。
参考链接:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu
官方给出的Python API使用文档,代码如下:
class BaiduPicDetect:
def __init__(self):
self.AK = "你的API Key"
self.SK = "Secret Key"
self.headers = {
"Content-Type": "application/json; charset=UTF-8"
}
# 通过AK和SK得到access_token值
def get_access_token(self):
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + self.AK + '&client_secret=' + self.SK
response = requests.get(host, headers=self.headers)
json_result = json.loads(response.text)
return json_result['access_token']
启动开发,目前AI产品主要有两种方式使用:API与SDK,您可以选择各产品的文档
篇幅原因,具体使用请参考:http://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjgn3
百度人脸检测API目前支持三种图片数据类型:一种就是BASE64;第二种是URL,也就是在线的图片源地址;第三种是FACE_TOKEN。
我们是将图片下载到了本地,所以我们需要将图片转成BASE64
# 注意下面两个方法也是BaiduPicDetect类中的方法
# 要将识别的图片转成base64格式
def img_to_base64(slef, path):
with open(path, 'rb') as f:
base64_data = base64.b64encode(f.read())
return base64_data
# 开始检测每一张图片
def detect_face(self, img_src):
..... # 代码太多回复给源码
return age, beauty, gender
类我们封装完毕之后,我们开始遍历我们下载的图片进行颜值测评了,并且我们把测评的数据保存到csv文件中。
def beauty_check(path):
...... # 遍历path文件夹并将测评数据保存到DataFrame中,其中df即DataFrame对象
return df
if __name__ == '__main__':
# 当前py文件与girl文件夹在同级,而图片都在girl文件夹中(仅是美女的图片哦!也可以创建boy的文件夹放帅哥)
path = 'girl'
result = beauty_check(path)
result.to_csv('./girl/颜值测评.csv', index=False)
print('finish!')
整体结构是这样的:
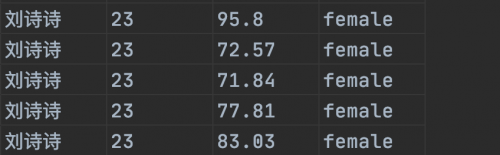
下载后的csv数据如下(温馨提示这个也跟图片有关)哈哈哈年龄好年轻啊!
数据分析
下面就开始我们的数据分析部分啦!代码很简单了。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 处理中文问题 我是Mac系统
data= pd.read_csv('./girl.csv',error_bad_lines=False)
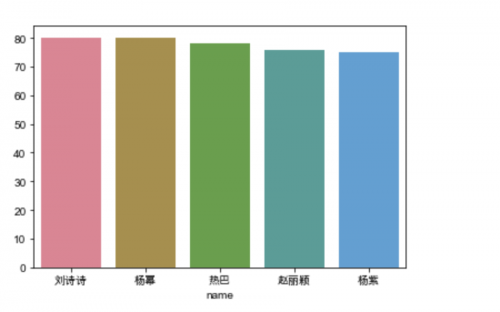
由于我们获取了多位美女的多张图片,所以我们要求一下每位美女的颜值平均值,所以我们按照名字进行分组,并求颜值的平均值。
下面的代码我们进行了一下排序:
beauty = data.groupby('name')['beauty'].mean().sort_values(ascending=False)
对分组求平均值后的数据进行可视化展示
sns.barplot(x=beauty.index,y=beauty.values,palette=sns.color_palette('husl'))
结果出来了:
由于篇幅问题,有些代码省略了,有需要的朋友!可以索要源码哦!














 京公网安备 11010802030320号
京公网安备 11010802030320号