


在 Scrapy 中要抓取和解析一些逻辑内容和提取网站的链接,其实都是需要在 Spider 中完成的。在上一篇文章中我们介绍了Scarpy框架的简单使用,后面一些文章我们要陆续介绍框架里面的Spider、配置、管道、中间件等。scrapy 框架分为spider爬虫和CrawlSpider(规则爬虫),本篇文章主要介绍Spider爬虫的使用。
spider
在实现 Scrapy 爬虫项目时,最核心的类就是 Spider 类了,它定义了如何爬取某个网站的流程和解析方式。简单来讲,Spider 要做的事就是如下两件。
• 定义爬取网站的动作
• 分析爬取下来的网页
对于 Spider 类来说,整个爬取循环如下所述。
• 以初始的 URL 初始化 Request,并设置回调函数。 当该 Request 成功请求并返回时,将生成 Response,并作为参数传给该回调函数。
• 在回调函数内分析返回的网页内容。返回结果可以有两种形式,一种是解析到的有效结果返回字典或 Item 对象。下一步可经过处理后(或直接)保存,另一种是解析得下一个(如下一页)链接,可以利用此链接构造 Request 并设置新的回调函数,返回 Request。
• 如果返回的是字典或 Item 对象,可通过 Feed Exports 等形式存入到文件,如果设置了 Pipeline 的话,可以经由 Pipeline 处理(如过滤、修正等)并保存。
• 如果返回的是 Reqeust,那么 Request 执行成功得到 Response 之后会再次传递给 Request 中定义的回调函数,可以再次使用选择器来分析新得到的网页内容,并根据分析的数据生成 Item。
通过以上几步循环往复进行,便完成了站点的爬取。
我们以星巴克网站为例,为大家介绍Spider类,首先创建项目和创建爬虫,具体步骤如下:
scrapy startproject starbuckspro
进入starbuckspro中,执行scrapy genspider starbucks https://www.starbucks.com.cn
此时我们就可以看到,有爬虫文件产生如图:
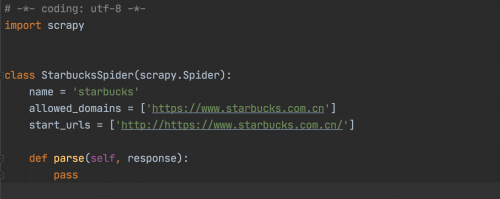
此时大家看到类:StarbucksSpider继承自scrapy.Spider,这个类是最简单最基本的 Spider 类,任何其他的 Spider 必须继承这个类,包括后文要说明的一些特殊 Spider 类也都是继承自它。这个类里提供了 startrequests () 方法的默认实现,读取并请求 starturls 属性,并根据返回的结果调用 parse () 方法解析结果。另外它还有一些基础属性,下面对其进行讲解:
name: 爬虫名称,是定义 Spider 名字的字符串。Spider 的名字定义了 Scrapy 如何定位并初始化 Spider,所以其必须是唯一的。如果该 Spider 爬取单个网站,一个常见的做法是以该网站的域名名称来命名 Spider。
allowed_domains:允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取。
start_urls:起始 URL 列表,当我们没有实现 start_requests () 方法时,默认会从这个列表开始抓取。
当然还有custom_settings和settings,可以进行一些设置或者获取一些全局的设置。而crawler属性是由 from_crawler () 方法设置的,代表的是本 Spider 类对应的 Crawler 对象。
除了一些基础属性,Spider 还有一些常用的方法:
start_requests ():此方法用于生成初始请求,它必须返回一个可迭代对象,此方法会默认使用 start_urls 里面的 URL 来构造 Request,而且 Request 是 GET 请求方式。如果我们想在启动时以 POST 方式访问某个站点,可以直接重写这个方法,发送 POST 请求时我们使用 FormRequest 即可。
parse ():当 Response 没有指定回调函数时,该方法会默认被调用,它负责处理 Response,处理返回结果,并从中提取出想要的数据和下一步的请求,然后返回。该方法需要返回一个包含 Request 或 Item 的可迭代对象。
closed ():当 Spider 关闭时,该方法会被调用,在这里一般会定义释放资源的一些操作或其他收尾操作。
当前星巴克的菜单页面如上图,我们要爬取里面的所有菜单名称和图片。parse()方法在 Response 没有指定回调函数时,会默认被调用。所以里面的参数response就是我们获取的页面结果,我们要从页面中提取想要的菜单名称和图片链接地址进行保存。于是我们要重写parse()方法和定义Item.py文件
Item
在抓取数据的过程中,主要要做的事就是从杂乱的数据中提取出结构化的数据。Scrapy的Spider可以把数据提取为一个Python中的字典,虽然字典使用起来非常方便,对我们来说也很熟悉,但是字典有一个缺点:缺少固定结构。在一个拥有许多爬虫的大项目中,字典非常容易造成字段名称上的语法错误,或者是返回不一致的数据。
所以Scrapy中,定义了一个专门的通用数据结构:Item。这个Item对象提供了跟字典相似的API,并且有一个非常方便的语法来声明可用的字段。
我们的Item的代码内容如下(因为只需要保存名称和图片链接即可):
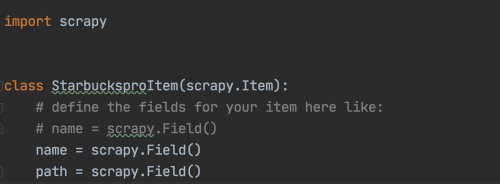
构建items.py文件完成后,还需要进一步处理爬取的数据,这就需要修改该项目中的pipelines.py文件。
Pipeline
Item Pipeline 是项目管道。也是保存结构数据的地。它的调用发生在 Spider 产生 Item 之后。当 Spider 解析完 Response 之后,Item 就会传递到 Item Pipeline,被定义的 Item Pipeline 组件会顺次调用,完成一连串的处理过程,比如数据清洗、存储等。 它的主要功能有:
• 清洗 HTML 数据
• 验证爬取数据,检查爬取字段
• 查重并丢弃重复内容
• 将爬取结果储存到数据库
定义Item非常简单,只需要继承scrapy.Item类,并将所有字段都定义为scrapy.Field类型即可。Field对象可用来对每个字段指定元数据。
其中经常使用的方法就是processitem () ,被定义的 Item Pipeline 会默认调用这个方法对 Item 进行处理。比如,我们可以进行数据处理或者将数据写入到数据库等操作。它必须返回 Item 类型的值或者抛出一个 DropItem 异常。 processitem () 方法的参数有如下两个。
• item,是 Item 对象,即被处理的 Item
• spider,是 Spider 对象,即生成该 Item 的 Spider
所以我们的Pipeline代码如下(将数据存储到数据库中):
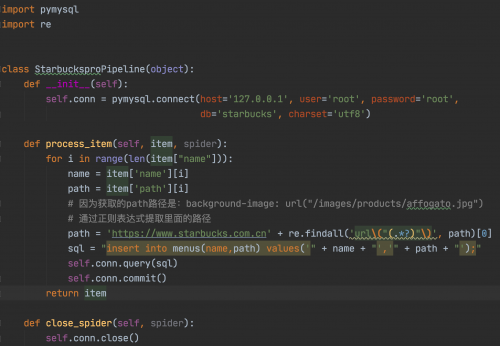
注意在settings.py中设置当前的Pipeline。

为了避免被发现爬虫我们还可以在settings.py中,如下设置:


准备活动完成后,我们开始编写我们的爬虫文件,爬取页面的分析如下图
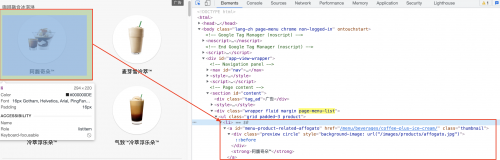
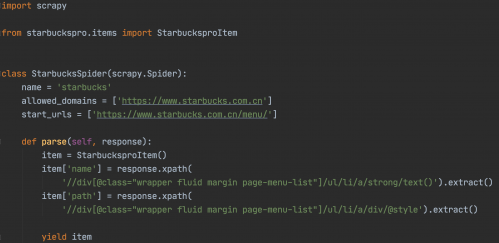
执行爬虫通过命令:scrapy crawl starbucks,则最后的下载数据结果如下:
















 京公网安备 11010802030320号
京公网安备 11010802030320号