


为什么要做逆向
动态网页爬虫一般可分为两种:Selenium爬取和接口爬取。两种方式各有优缺点:前者我们己经介绍了selenium的使用和验证码、滑块的使用,其虽然可以很好地处理网页异步加载问题,但面对大型爬虫任务时,效率还是比较低的;后者虽然爬取速度较快,但请求参数很可能是动态变化的,这时就需要利用一些前端的知识,重新构造参数,整个过程通常称为JS逆向。先来看一下简单的请求:
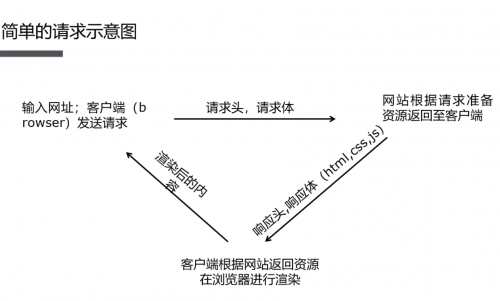
但是往往在我们编写爬虫时,可能会碰到以下两种问题:
• 所需要爬取的数据在网页源代码中并不存在;
• 点击下一页跳转页面时,网页的URL 并没与发生变化;
造成这种问题原因是,你所正在爬取的页面采取了动态加载的方式
动态加载网页其显示的页面则是经过Javascript处理数据后生成的结果,可以发生改变。
JavaScript是一种运行在浏览器中的解释型编程语言,JavaScript非常值得学习,它既适合作为学习编程的入门语言,也适合当作日常开发的工作语言。JavaScript可以收集用户的跟踪数据,不需要重载页面即可直接提交表单,可在页面中嵌入多媒体文件,甚至可以运行网页游戏等。在很多看起来非常简单的页面背后通常使用了许多JavaScript文件。比如:

这些数据的来源有多种,可能是经过Javascript计算生成的,也可能是通过Ajax加载的。Ajax = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML),其最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页的内容。
逆向工程
对于动态加载的网页,我们想要获取其网页数据,需要了解网页是如何加载数据的,该过程就被成为逆向工程。
对于使用了Ajax 请求技术的网页,我们可以找到Ajax请求的具体链接,直接得到Ajax请求得到的数据。
需要注意的是,构造Ajax请求有两种方式:
• 原生的Ajax请求,会直接创建一个XMLHTTPRequest对象。
• 调用jQuery的ajax()方法。一般情况下,$.ajax()会返回其创建的XMLHTTPRequest对象;但是,如果$.ajax()的dataType参数指定了为script或jsonp类型,$.ajax()不再返回其创建的XMLHTTPRequest对象。
JQuery补充:
在大型互联网公司的不断推广下,JavaScript生态圈也在不断的完善,各种类库、API接口层出不穷。
jQuery是一个快速、简洁的JavaScript框架,是继Prototype之后又一个优秀的JavaScript代码库(或JavaScript框架)。jQuery设计的宗旨是“Write Less, Do More”,即倡导写更少的代码,做更多的事情。
对于这两种方式,只要创建返回了XMLHTTPRequest对象,就可以通过Chrome浏览器的调试工具在NetWork窗口通过设置XHR过滤条件,直接筛选出Ajax请求的链接;如果是$.ajax()并且dataType指定了为script或jsonp,则无法通过这种方式筛选出来。
案例分析
这次搞得还是滑块哦���,话不多说直接开搞数美滑块,因为小红书、蘑菇街、脉脉、斗鱼等很多都用了数美的验证码。整体难度还可以就是动态参数有点东西的呢!
数美验证码官网:https://www.ishumei.com/trial/captcha.html
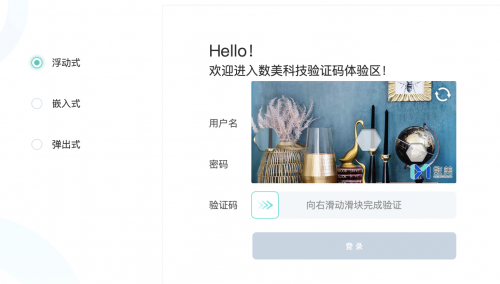
数美滑块的验证码主要的难点有以下几点:
request的请求参数,是动态变化的。名称是动态变化,加密的密钥也是动态变化的,这就有点难搞了
每天小版本更新的频率1-2次,必须得能够实现完全自动化,否则人工很难及时的调整验证码的参数,来不及。
js里的混淆的变量也是动态变化的
验证码注册
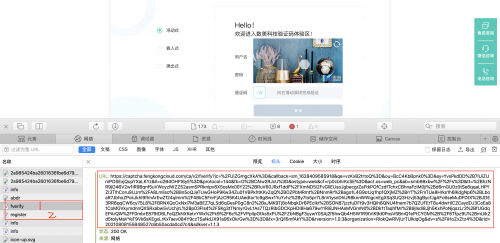
先看一下register

下图是响应结果:bg和fg是验证码图片地址 https://castatic.fengkongcloud.com/bg
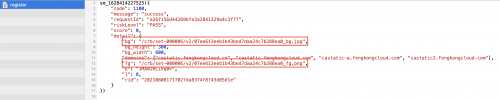
计算滑块位置
根据上一步可以得到验证图片的地址。
验证码图片:https://castatic.fengkongcloud.com/crb/set-000006/v2/07ee613eeb1b43bed7daa24c7b288ea0bg.jpg
滑块图片:https://castatic.fengkongcloud.com/crb/set-000006/v2/07ee613eeb1b43bed7daa24c7b288ea0fg.png
使用opencv查找并匹配图像模板中的滑块。
需要注意的是,这里是以原图计算的,而页面上的图片大小只有(300,150),(应用不同的产品可能大小也不同)
所以需要按比例进行缩小或者放大。
验证
对应的api地址是:https://captcha.fengkongcloud.com/ca/v2/fverify?...

查询字符串参数:

params参数里的 dv,qe,ou,cf等等,都经过了DES加密,
破解方式分析
打开控制台多看几遍请求过程,我们基本就明白请求步骤了。具体的分析过程就不再赘述。
所携带的请求参数如下:
该接口返回的js参数,是下一步需要请求的目标。
提取js参数
js地址:https://castatic.fengkongcloud.com/pr/auto-build/v1.0.3-144/captcha-sdk.min.js
需要提取该js中的参数名,会在最后验证的时候使用(注:一般情况下参数名不会变),但是这些请求参数都是变化的。
获取js的response,搜索上面的参数我们没有找到,但是发现了倒序的名字
通过查看调用栈,打断点,一层层分析,发现js做了ob混淆。
JS混淆有很多种,这里举几个:UglifyJS,JScrambler,jsbeautifier.org,JSDetox,obfuscator.io 等,像下面的代码就是ob混淆。
开头定义了一个大数组,然后对这个大数组里的内容进行位移,再定义一个解密函数。后面大部分的值都调用了这个解密函数,以达到混淆的效果。如果想还原可以使用ob混淆还原工具:https://github.com/DingZaiHub/ob-decrypt
当然不进行混淆还原也可以通过断点很快的定位到具体的函数加密的位置
再次请求走到这里,而这里是一部分的参数的加密,先进去看下它是怎么加密的
进来了走到这可以看到是DES加密,参数分别是加密的密码,要加密的参数,后面两个是数字呢就是模式选择了,1,0是加密,0,0是解密,在这里是加密。
我们输出在console中输出一下,这四个参数看一下
那么问题来了,这个密码"b64ccadf"哪来的呢,别急,我们重新再来一遍!很快我们又进来走到这,_0x1c2865是什么怎么是乱码的呢?
console输出一下看看

密码搞到了,加密方式也晓得了,然后参数一个一个整过去就Ok了。
返回结果response:

message = success,riskLevel=PASS 说明验证通过
完整代码
"""
数美滑块验证码破解验证
"""
import base64
import json
import random
import re
import time
from io import BytesIO
import cv2
import numpy as np
import requests
from pyDes import des, ECB
CAPTCHA_DISPLAY_WIDTH = 310
CAPTCHA_DISPLAY_HEIGHT = 155
p = {}
def pad(b):
"""
块填充
"""
block_size = 8
while len(b) % block_size:
b += b'\0'
return b
def split_args(s):
"""
分割js参数
"""
r = []
a = ''
i = 0
while i < len(s):
c = s[i]
if c == ',' and (a[0] != '\'' or len(a) >= 2 and a[-1] == '\''):
r.append(a)
a = ''
elif c:
a += c
i += 1
r.append(a)
return r
def find_arg_names(script):
"""
通过js解析出参数名
"""
names = {}
a = []
for r in re.findall(r'function\((.*?)\)', script):
if len(r.split(',')) > 100:
a = split_args(r)
break
r = re.search(r';\)(.*?)\(}', script[::-1]).group(1)
v = split_args(r[::-1])
d = r'{%s}' % ''.join([((',' if i else '') + '\'k{}\':([_x0-9a-z]*)'.format(i + 1)) for i in range(15)])
k = []
r = re.search(d, script)
for i in range(15):
k.append(r.group(i + 1))
n = int(v[a.index(re.search(r'arguments;.*?,(.*?)\);', script).group(1))], base=16)
for i in range(n // 2):
v[i], v[n - 1 - i] = v[n - 1 - i], v[i]
for i, b in enumerate(k):
t = v[a.index(b)].strip('\'')
names['k{}'.format(i + 1)] = t if len(t) > 2 else t[::-1]
return names
def get_encrypt_content(message, key, flag):
"""
接口参数的加密、解密
"""
des_obj = des(key.encode(), mode=ECB)
if flag:
content = pad(str(message).replace(' ', '').encode())
return base64.b64encode(des_obj.encrypt(content)).decode('utf-8')
else:
return des_obj.decrypt(base64.b64decode(message)).decode('utf-8')
def get_random_ge(distance):
"""
生成随机的轨迹
"""
ge = []
y = 0
v = 0
t = 1
current = 0
mid = distance * 3 / 4
exceed = 20
z = t
ge.append([0, 0, 1])
while current < (distance + exceed):
if current < mid / 2:
a = 15
elif current < mid:
a = 20
else:
a = -30
a /= 2
v0 = v
s = v0 * t + 0.5 * a * (t * t)
current += int(s)
v = v0 + a * t
y += random.randint(-5, 5)
z += 100 + random.randint(0, 10)
ge.append([min(current, (distance + exceed)), y, z])
while exceed > 0:
exceed -= random.randint(0, 5)
y += random.randint(-5, 5)
z += 100 + random.randint(0, 10)
ge.append([min(current, (distance + exceed)), y, z])
return ge
def make_mouse_action_args(distance):
"""
生成鼠标行为相关的参数
"""
ge = get_random_ge(distance)
args = {
p['k']['k5']: round(distance / CAPTCHA_DISPLAY_WIDTH, 2),
p['k']['k6']: get_random_ge(distance),
p['k']['k7']: ge[-1][-1] + random.randint(0, 100),
p['k']['k8']: CAPTCHA_DISPLAY_WIDTH,
p['k']['k9']: CAPTCHA_DISPLAY_HEIGHT,
p['k']['k11']: 1,
p['k']['k12']: 0,
p['k']['k13']: -1,
'act.os': 'android'
}
return args
def get_distance(fg, bg):
"""
计算滑动距离
"""
target = cv2.imdecode(np.asarray(bytearray(fg.read()), dtype=np.uint8), 0)
template = cv2.imdecode(np.asarray(bytearray(bg.read()), dtype=np.uint8), 0)
result = cv2.matchTemplate(target, template, cv2.TM_CCORR_NORMED)
_, distance = np.unravel_index(result.argmax(), result.shape)
return distance
def update_protocol(protocol_num, js_uri):
"""
更新协议
"""
global p
r = requests.get(js_uri, verify=False)
names = find_arg_names(r.text)
p = {
'i': protocol_num,
'k': names
}
def conf_captcha(organization):
"""
获取验证码设置
"""
url = 'https://captcha.fengkongcloud.com/ca/v1/conf'
args = {
'organization': organization,
'model': 'slide',
'sdkver': '1.1.3',
'rversion': '1.0.3',
'appId': 'default',
'lang': 'zh-cn',
'channel': 'YingYongBao',
'callback': 'sm_{}'.format(int(time.time() * 1000))
}
r = requests.get(url, params=args, verify=False)
resp = json.loads(re.search(r'{}\((.*)\)'.format(args['callback']), r.text).group(1))
return resp
def register_captcha(organization):
"""
注册验证码
"""
url = 'https://captcha.fengkongcloud.com/ca/v1/register'
args = {
'organization': organization,
'channel': 'DEFAULT',
'lang': 'zh-cn',
'model': 'slide',
'appId': 'default',
'sdkver': '1.1.3',
'data': '{}',
'rversion': '1.0.3',
'callback': 'sm_{}'.format(int(time.time() * 1000))
}
r = requests.get(url, params=args, verify=False)
resp = json.loads(re.search(r'{}\((.*)\)'.format(args['callback']), r.text).group(1))
return resp
def verify_captcha(organization, rid, key, distance):
"""
提交验证
"""
url = 'https://captcha.fengkongcloud.com/ca/v2/fverify'
args = {
'organization': organization,
p['k']['k1']: 'default',
p['k']['k2']: 'YingYongBao',
p['k']['k3']: 'zh-cn',
'rid': rid,
'rversion': '1.0.3',
'sdkver': '1.1.3',
'protocol': p['i'],
'ostype': 'web',
'callback': 'sm_{}'.format(int(time.time() * 1000))
}
args.update(make_mouse_action_args(distance))
key = get_encrypt_content(key, 'sshummei', 0)
for k, v in args.items():
if len(k) == 2:
args[k] = get_encrypt_content(v, key, 1)
print(args)
r = requests.get(url, params=args, verify=False)
resp = json.loads(re.search(r'{}\((.*)\)'.format(args['callback']), r.text).group(1))
return resp
def get_verify(organization):
"""
进行验证
"""
resp = conf_captcha(organization)
protocol_num = re.search(r'build/v1.0.3-(.*?)/captcha-sdk.min.js', resp['detail']['js']).group(1)
if not p.get('id') or protocol_num != p['i']:
update_protocol(protocol_num, ''.join(['https://', resp['detail']['domains'][0], resp['detail']['js']]))
resp = register_captcha(organization)
rid = resp['detail']['rid']
key = resp['detail']['k']
domain = resp['detail']['domains'][0]
fg_uri = resp['detail']['fg']
bg_uri = resp['detail']['bg']
fg_url = ''.join(['http://', domain, fg_uri])
bg_url = ''.join(['http://', domain, bg_uri])
r = requests.get(fg_url, verify=False)
fg = BytesIO(r.content)
r = requests.get(bg_url, verify=False)
bg = BytesIO(r.content)
distance = get_distance(fg, bg)
print(distance)
r = verify_captcha(organization, rid, key, int(distance / 600 * 310))
return rid, r
def test():
organization = 'RlokQwRlVjUrTUlkIqOg'
# rid是验证过程中响应的标示,r是最后提交验证返回的响应
rid, r = get_verify(organization)
print(rid, r)
# riskLevel为PASS说明验证通过
if r['riskLevel'] == 'PASS':
# 具体可抓包查看,接口:/api/sns/v1/system_service/slide_captcha_check
pass
if __name__ == '__main__':
test()
大家用同样的方法赶快试一试小红书,蘑菇街等网站登陆吧!















 京公网安备 11010802030320号
京公网安备 11010802030320号