


极验给大家简单介绍一下:https://www.geetest.com/,在这里给大家提供了智能组合、滑块验证、点选验证的体验。
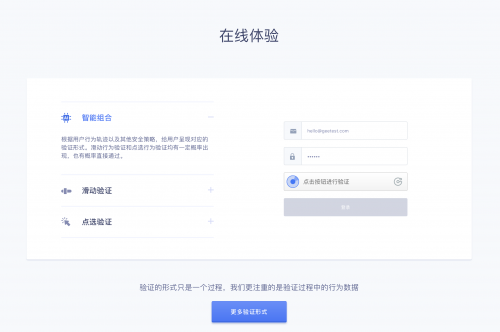
滑块验证就是其中一部分,而像B站、斗鱼、简书、小米、汽车之家等都是他的客户。如果大家感兴趣也可以去其他网站试试,再次强调B站我还是很喜欢的
滑块验证码简述
有爬虫,自然就有反爬虫,就像病毒和杀毒软件一样,有攻就有防,两者彼此推进发展。而目前最流行的反爬技术验证码,为了防止爬虫自动注册,批量生成垃圾账号,几乎所有网站的注册页面都会用到验证码技术。其实验证码的英文为 CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart),翻译成中文就是全自动区分计算机和人类的公开图灵测试,它是一种可以区分用户是计算机还是人的测试,只要能通过 CAPTCHA 测试,该用户就可以被认为是人类。由此也可知道破解滑块验证码的关键即是让计算机更好的模拟人的行为,这也是破解的难点所在。
配置环境
环境要求:
安装Python3
pip install selenium pillow
selenium 安装完成后,下载所选浏览器的 webdriver,这个前面一篇文章已经介绍过,不再重复介绍(注意下载的ChromeDriver版本需与Chrome浏览器版本对应)
破解步骤
思路分析:
利用selenium进入滑块验证码页面,截取所需页面图片。
通过图片像素对比分析获取缺口位置与滑块移动距离。
机器模拟人工滑动轨迹。
难点分析:
这类验证码可以使用 selenium 操作浏览器拖拽滑块来进行破解,难点两个,一个如何确定拖拽到的位置,另一个是避开人机识别(反爬虫)。
首先我们先看看,确定滑块验证码需要拖拽的位移距离
有三种方式
• 人工智能机器学习,确定滑块位置
• 通过完整图片与缺失滑块的图片进行像素对比,确定滑块位置
• 边缘检测算法,确定位置
各有优缺点。人工智能机器学习,确定滑块位置,需要进行训练比较麻烦,所以我们主要看后面两种。
对比完整图片与缺失滑块的图片
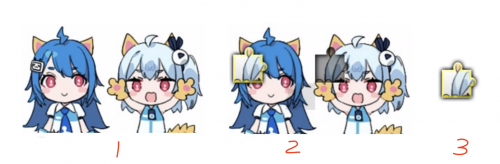
B站的滑块验证模块,一共有三张图片:完整图、缺失滑块图、滑块图,都是由画布canvas绘制出的。类似于:
下面三张图:
HTML截图如下:
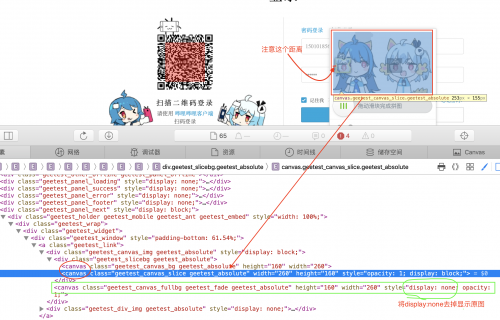
只需要通过selenium获取画布元素,执行js拿到画布像素,遍历完整图和缺失滑块图的像素,一旦获取到差异(需要允许少许像素误差),像素矩阵x轴方向即是滑块位置。另外由于滑块图距离画布坐标原点有距离,还需要减去这部分距离。最后使用 selenium 拖拽即可。
部分代码如下(结合selenium完成):
# 屏幕截图
def get_screenshot(self):
"""
获取网页截图
:return: 截图对象
"""
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
x, y = screenshot.size
screenshot.resize((int(x / 2), int(y / 2)), Image.ANTIALIAS).save('screenshot.png')
screenshot = Image.open('screenshot.png')
return screenshot
# 计算验证码图片所在的位置
def get_position(self):
"""
获取验证码位置
:return: 验证码位置元组
"""
top = self.browser.execute_script("return document.documentElement.scrollTop")
print(top)
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_canvas_bg')))
print(img)
location = img.location
size = img.size
top, bottom, left, right = location['y'] - top, location['y'] - top + size['height'], location['x'], \
location['x'] + size['width']
return (top, bottom, left, right)
# 该动作会调用两次,分别获取原图和带缺口的图
def get_geetest_image(self, name='captcha.png'):
"""
获取验证码图片
:return: 图片对象
"""
top, bottom, left, right = self.get_position()
print('验证码位置', left, top, right, bottom)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
# 获取缺口的尺寸
def get_gap(self, image1, image2):
"""
获取缺口偏移量
:param image1: 带缺口图片
:param image2: 不带缺口图片
:return:
"""
left = 60
print(image1.size[0])
print(image1.size[1])
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
# 比较两张截图的不同
def is_pixel_equal(self, image1, image2, x, y):
"""
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取两个图片的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
边缘检测算法,确定位置
滑块基本上是个方形,通过算法确定方形起始位置即可。

滑块是方形的,存在垂直与水平的边,该边在缺失滑块图中基本都是灰黑的。遍历像素找到基本都是灰黑的边即可。这种实现方式会存在检测不出或错误的情况,使用时需要换一张验证码。也可能存在检测出的边是另一条(因为B站的滑块不是长方形,存在弧形边),那么需要减去滑块宽度。
代码如下(结合selenium完成):
class VerifyImageUtil():
def __init__(self):
self.defaultConfig = {
"grayOffset": 20,
"opaque": 1,
"minVerticalLineCount": 30
}
self.config = copy.deepcopy(self.defaultConfig)
def updateConfig(self, config):
for k in self.config:
if k in config.keys():
self.config[k] = config[k]
def getMaxOffset(self, *args):
# 计算偏移平均值最大的数
av = sum(args) / len(args)
maxOffset = 0
for a in args:
offset = abs(av - a)
if offset > maxOffset:
maxOffset = offset
return maxOffset
def isGrayPx(self, r, g, b):
# 是否是灰度像素点,允许波动offset
return self.getMaxOffset(r, g, b) < self.config["grayOffset"]
def isDarkStyle(self, r, g, b):
# 灰暗风格
return r < 128 and g < 128 and b < 128
def isOpaque(self, px):
# 不透明
return px[3] >= 255 * self.config["opaque"]
def getVerticalLineOffsetX(self, bgImage):
bgBytes = bgImage.load()
x = 0
while x < bgImage.size[0]:
y = 0
# 点,线,灰度线条数量
verticalLineCount = 0
while y < bgImage.size[1]:
px = bgBytes[x, y]
r = px[0]
g = px[1]
b = px[2]
if self.isDarkStyle(r, g, b) and self.isGrayPx(r, g, b) and self.isOpaque(px):
verticalLineCount += 1
else:
verticalLineCount = 0
y += 1
continue
if verticalLineCount >= self.config["minVerticalLineCount"]:
# 连续多个像素都是灰度像素,直线,认为需要滑动这么多
# print(x, y)
return x
y += 1
x += 1
完整步骤
本案例采用的是边缘检测算法。
步骤一:启动selenium,获取验证码图片,方便查看预览
from selenium import webdriver
import time
import base64
from PIL import Image
from io import BytesIO
from selenium.webdriver.support.ui import WebDriverWait
def checkVeriImage(driver):
# 等待画布加载完毕
WebDriverWait(driver, 5).until(
lambda driver: driver.find_element_by_css_selector('.geetest_canvas_bg.geetest_absolute'))
time.sleep(1)
# 获取有缺口的图片
im_info = driver.execute_script(
'return document.getElementsByClassName("geetest_canvas_bg geetest_absolute")[0].toDataURL("image/png");')
# 得到base64编码的图片信息
im_base64 = im_info.split(',')[1]
# 转为bytes类型
im_bytes = base64.b64decode(im_base64)
with open('./tempbg.png', 'wb') as f:
# 保存图片到本地,方便查看预览
f.write(im_bytes)
image_data = BytesIO(im_bytes)
bgImage = Image.open(image_data)
# 计算offsetx的长度
offsetX = VerifyImageUtil().getVerticalLineOffsetX(bgImage)
# 获取滑块按钮
eleDrag = driver.find_element_by_css_selector(".geetest_slider_button")
action_chains = webdriver.ActionChains(driver)
# 拖动滑块按钮,注意滑块距离左边有 5~10 像素左右误差
action_chains.drag_and_drop_by_offset(eleDrag,offsetX-10,0).perform()
貌似没有问题了,但是总是出现这句话:拼图被怪物吃掉了,请重试。这是因为被检测到机器人(爬虫)操作了。所以我们滑动的动作要更像我们人为的行为。如何避开人机的识别?分析原因是:webdriver.ActionChains(driver).draganddropbyoffset(eleDrag,offsetX-10,0).perform() 拖动滑块动作太快了的缘故。当然期间宋宋也这样实现过:
action_chains = webdriver.ActionChains(driver)
action_chains.click_and_hold(slider).perform()
action_chains.pause(0.2)
ran = random.randint(1,50)
action_chains.move_by_offset(xoffset=distance - ran, yoffset=0)
action_chains.pause(0.6)
action_chains.move_by_offset(xoffset=ran-10, yoffset=0)
action_chains.pause(0.5)
action_chains.move_by_offset(xoffset=4, yoffset=0)
action_chains.pause(0.4)
action_chains.move_by_offset(xoffset=5, yoffset=0)
action_chains.pause(0.6)
action_chains.move_by_offset(xoffset=1, yoffset=0)
action_chains.pause(0.6)
action_chains.release()
action_chains.perform()
就是慢点实现多拖动几次并且加入了休眠,但是这么做还是不会成功的,仍然会提示:拼图被怪物吃掉了,请重试
稍微改进一下(使用了 actionchains.moveby_offset(10,0)用于修正):
action_chains = webdriver.ActionChains(self.driver)
# 点击,准备拖拽
action_chains.click_and_hold(source)
action_chains.pause(0.2)
action_chains.move_by_offset(targetOffsetX-10,0)
action_chains.pause(0.6)
action_chains.move_by_offset(10,0)
action_chains.pause(0.6)
action_chains.release()
action_chains.perform()
但是验证成功的概率也是挺低的。为了更像人类操作,可以进行拖拽间隔时间和拖拽次数、距离的随机化,于是来个更加完美版。
def simulateDragX(self, source, targetOffsetX):
"""
模仿人的拖拽动作:快速沿着X轴拖动(存在误差),再暂停,然后修正误差
防止被检测为机器人,出现“图片被怪物吃掉了”等验证失败的情况
:param source:要拖拽的html元素
:param targetOffsetX: 拖拽目标x轴距离
:return: None
"""
action_chains = webdriver.ActionChains(self.driver)
# 点击,准备拖拽
action_chains.click_and_hold(source)
# 拖动次数,二到三次
dragCount = random.randint(2, 3)
if dragCount == 2:
# 总误差值
sumOffsetx = random.randint(-15, 15)
action_chains.move_by_offset(targetOffsetX + sumOffsetx, 0)
# 暂停一会
action_chains.pause(self.__getRadomPauseScondes())
# 修正误差,防止被检测为机器人,出现图片被怪物吃掉了等验证失败的情况
action_chains.move_by_offset(-sumOffsetx, 0)
elif dragCount == 3:
# 总误差值
sumOffsetx = random.randint(-15, 15)
action_chains.move_by_offset(targetOffsetX + sumOffsetx, 0)
# 暂停一会
action_chains.pause(self.__getRadomPauseScondes())
# 已修正误差的和
fixedOffsetX = 0
# 第一次修正误差
if sumOffsetx < 0:
offsetx = random.randint(sumOffsetx, 0)
else:
offsetx = random.randint(0, sumOffsetx)
fixedOffsetX = fixedOffsetX + offsetx
action_chains.move_by_offset(-offsetx, 0)
action_chains.pause(self.__getRadomPauseScondes())
# 最后一次修正误差
action_chains.move_by_offset(-sumOffsetx + fixedOffsetX, 0)
action_chains.pause(self.__getRadomPauseScondes())
else:
raise Exception("莫不是系统出现了问题?!")
action_chains.release().perform()
哇!真的成功啦!完美!















 京公网安备 11010802030320号
京公网安备 11010802030320号