


在过去的文章中,我们讨论了很多关于 V8 的 JavaScript 编译器。解析器,扫描程序和字节码,以及它们的基本原理,内核代码和密钥结构,都是我们介绍的。

在接下来的文章中,我们将逐步介绍编译器工作流程,并观察 V8 如何逐步将 JavaScript 代码转换为字节码。
V8从您编写的 JavaScript 代码开始,经过扫描程序和解析器,最后生成字节码。
注意:在本文中,我使用d8.exe而不是v8.exe,因为d8.exe可以直接打印到终端,并且d8与v8相比非常轻。
1. 阅读脚本代码
以下是我们的测试用例:
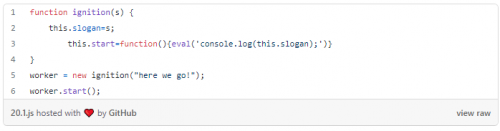
下面是负责执行 JavaScript 代码的执行()。很简单,它首先从文件中读取JavaScript代码,然后编译并执行代码。

在第 5 行中,新取自 8 获取文件名,这就是我们的情况。在第 8 行中,读取文件获取文件内容,这实际上是我们的情况。

第 8 行和第 10 行返回 JavaScript 代码,具体取决于类型是外部一字节或 UTF8。在这里,我们的例子是UTF8,关于字符串::外部一字节字符串资源,我们将在将来讨论它。
返回到源代码组::执行(),并在第 14 行单步执行::执行字符串,其源代码如下:

在第 13 行中,我们的 JavaScript 被包装到一个变量script_source其中包括行和列偏移量。由于 V8 只编译完全不是完整 JavaScript 代码执行的 JavaScript 函数,因此变量script_source帮助编译器记录编译信息。
在第 14 行中,开始编译脚本。
2. 解析器初始化
在工作流中,第一部分是扫描仪,第二部分是解析器。实际上,扫描程序是被动的,解析器是主动的,这意味着解析器主动地从编译缓存中取出一个令牌,一旦缓存未命中,扫描程序就会被解析器唤醒,并生成令牌并填充缓存。
下面是由脚本编译器调用的编译不受约束的内部():编译在第14行的上面。
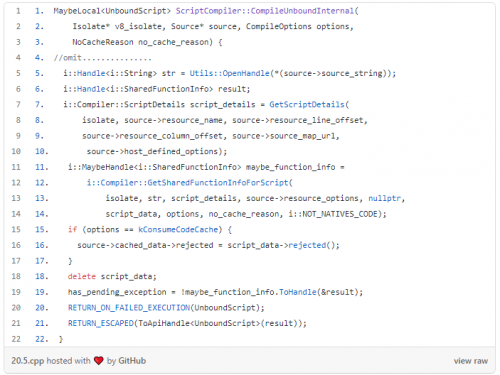
上面的函数生成了未绑定的内部内容,第 11 行告诉我们,这些内容实际上只是一个共享函数。但是,什么是绑定?共享函数不能直接执行,V8 需要将上下文与共享函数匹配,“匹配”只是必应。
让我们进入获取共享功能信息脚本。

第7行正在查找我在上一篇文章中提到的编译缓存。
第 13 行,parse_info是解析器的包装器,就像前面提到的变量script_source样。
第15行,Parser_info初始化,代码如下:

从第 6 行到第 12 行,将我们的情况中的 JavaScript 代码包装到变量脚本中,然后初始化line_offset并column_offset。就像我说的script_source样。
返回编译器::获取共享功能信息脚本(),然后在第 23 行单步执行编译顶级 ()。
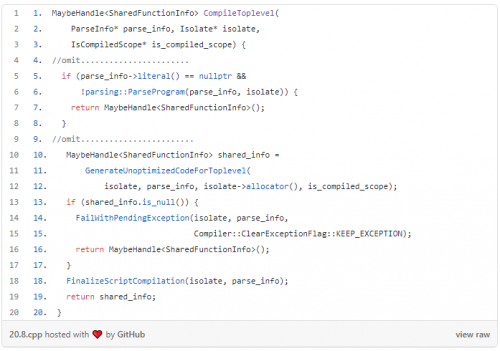
在第 5 行中,文本() 返回抽象语法树 (AST),如果为空,则 V8 启动编译器以生成 AST。
第一次,AST 为空,并单步执行解析程序。

在第 5 行中,创建解析器,即解析器初始化。

从第8行到第18行,取出编译信息,如扫描仪和编译模式。
从第9行到第23行,重要的东西是can_compile_lazily。
第 25 行启用以 % 开头的本机命令。
总结
V8 使用 UTF16 对脚本源代码进行编码;
V8 使用 v8::内部::源代码来管理我们的脚本代码;
首先,查找编译缓存,如果缓存未命中,则启动编译器;
扫描程序是被动的,分析器是主动的。

















 京公网安备 11010802030320号
京公网安备 11010802030320号