



综合案例
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC # available since 2.26.0
from selenium.webdriver.support.ui import WebDriverWait # available since 2.4.0
from selenium.webdriver.support import expected_conditions
import pandas as pd
class MyCrawler(object):
def __init__(self):
self.path = "./data"
if not os.path.exists(self.path):
os.mkdir(self.path)
self.driver = webdriver.Chrome()
self.base_url = "http://data.house.163.com/bj/housing/trend/district/todayprice/{date:s}/{interval:s}/allDistrict/1.html?districtname={disname:s}#stoppoint"
self.data = None
def craw_page(self, date="2020.01.01-2020.12.30", interval="month", disname="全市"):
driver = self.driver
url = self.base_url.format(date=date, interval=interval, disname=disname)
driver.get(url)
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "resultdiv_1")))
self.data = pd.DataFrame()
ct = True
while ct:
self.get_items_in_page(driver)
e_pages = driver.find_elements_by_xpath(
'//div[@class="pager_box"]/a[@class="pager_b current"]/following::a[@class="pager_b "]')
if len(e_pages) > 0:
next_page_num = e_pages[0].text
e_pages[0].click()
# 通过判断当前页是否为我们点击页面的方式来等待页面加载完成
WebDriverWait(driver, 10).until(
expected_conditions.text_to_be_present_in_element(
(By.XPATH, '//a[@class="pager_b current"]'),
next_page_num
)
)
else:
ct = False
brea
return self.data
finally:
driver.quit()
def get_items_in_page(self, driver):
e_tr = driver.find_elements_by_xpath("//tr[normalize-space(@class)='mBg1' or normalize-space(@class)='mBg2']")
temp = pd.DataFrame(e_tr, columns=['web'])
temp['时间'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd2').text.split(' ')[0])
temp['套数'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd5').text)
temp['均价'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd7').text)
temp['去化'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd14').text)
del temp['web']
self.data = pd.concat([temp, self.data], axis=0)
mcraw = MyCrawler()
data = mcraw.craw_page()
data= data.sort_values(by='时间')
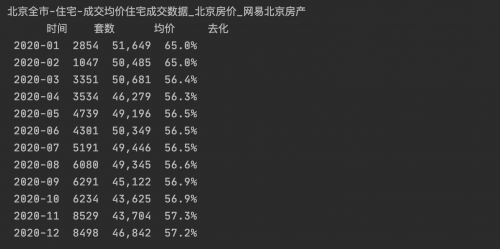
print(data.to_string(index=False))














 京公网安备 11010802030320号
京公网安备 11010802030320号