


我们今天写的爬虫内容是xpath,我们通过美食页面的分析带领大家学习xpath。
先来介绍一下xpath。 XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。 跟BeautifulSoup4一样都是用来解析页面内容的工具,只不过使用方式有所不同而已。
要想使用xpath,需要安装lxml: pip install lxml
案例分析
下面我们通过豆果网精选美食https://www.douguo.com/jingxuan/0来带领大家学习使用xpath。
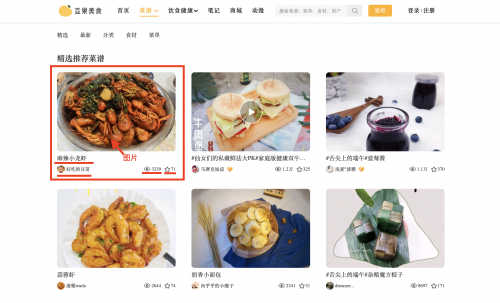
Picture
我们要获取菜谱的名称、作者、浏览量、收藏量、图片等信息,每页中有24个菜谱推荐。
看一下文章的节点情况:
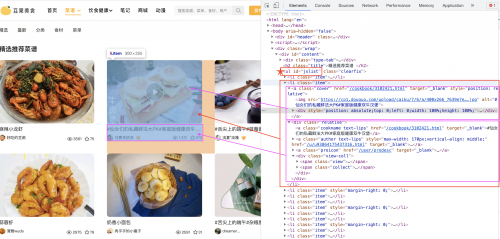
可以发现有多个li【类选择器是item的】标签,每个li里面包含两部分内容过:【a标签和div标签】
a标签中包含的是图片和视频内容过,
div标签中包含的信息是:菜谱的名称、作者、浏览量、收藏量
因此我们通过节点找到id=jxlist的ul标签,就可以获取里面的多个li标签。
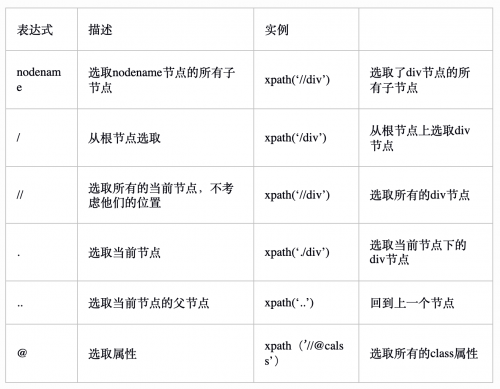
xpath节点选取语法
在介绍bs4的时候,我们已经给大家介绍了节点的概念,比如父节点、子节点、同胞节点、先辈节点和后代节点等。
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
常用的路径表达式有:
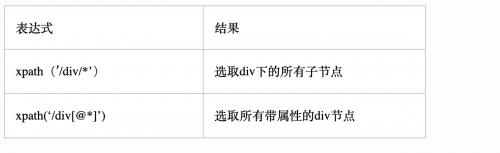
但是往往在查找的时候,我们需要获取某个特定的节点,则需要配合下面的方式即:被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点。

另外还可以在使用xpath的时候使用通配符和功能函数

案例使用
使用requests获取网页信息
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
response = requests.get('https://www.douguo.com/jingxuan/0', headers=headers)
# 为了写xpath内容,我们先将内容保存到本地,然后爬取多页内容
with open('jingxuan.html', 'wb') as stream:
stream.write(response.content)
我们分析页面内容并使用xpath,
获取美食的详情页链接
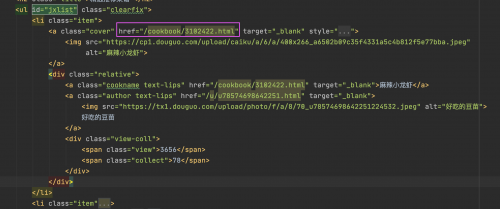
可以发现详情页的链接在a标签的href属性中,通过xpath获取可以使用:
//ul[@id="jxlist"]/li/a/@href
表示获取id叫jxlist的ul标签,注意此处使用了//,每一层的/表示一层关系
完整代码:
from lxml import etree
# 读取保存在本地的网页,进行xpath解析
with open('jingxuan.html', 'r') as stream:
all = stream.read()
html = etree.HTML(all)
links = html.xpath('//ul[@id="jxlist"]/li/a/@href')
print(links)
结果提取出了所有li中的详情页链接,当前如果访问要添加前缀(https://www.douguo.com)进行拼接:
['/cookbook/3102422.html', '/cookbook/3102421.html', '/cookbook/3102419.html', ..... ]
美食图片的获取,美食图片的链接在a标签的img标签中,所以代码要改成:
images = html.xpath('//ul[@id="jxlist"]/li/a/img/@src')
print(images)
获取了每个美食的图片链接,结果如下:
['https://cp1.douguo.com/upload/caiku/a/6/a/400x266_a6502b09c35f4331a5c4b812f5e77bba.jpeg', 'https://cp1.douguo.com/upload/caiku/7/6/a/400x266_7639e7ea6394437042e9b2f77414f84a.jpg',
......
]
菜名的获取,有两种方式:
在a标签的alt属性中获取
//ul[@id="jxlist"]/li/a/@alt
在div的第一个a标签中获取
//ul[@id="jxlist"]/li/div/a[1]/text()
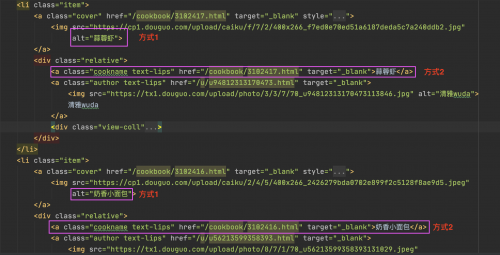
本次使用的是第二种方式,其中a[1]表示div中的第一个div标签。
names = html.xpath('//ul[@id="jxlist"]/li/div/a[1]/text()')
print(names)
结果:
['麻辣小龙虾', '#仙女们的私藏鲜法大PK#家庭版健康双牛汉堡', '#舌尖上的端午#蓝莓酱', '蒜蓉虾', '奶香小面包',......]
发表用户的获取
用户名在div的第二个a标签中,但是发现a标签不仅有文本还有img标签。按照上面的方式获取(注意文本的获取使用text())
//ul[@id="jxlist"]/li/div/a[2]/text()
发现结果,将文本的换行和空格内容都包含在里面了,而且每个文本的前面都有一个空内容:

于是我们需要进行正则的替换和获取有用信息。
import re
users = html.xpath('//ul[@id="jxlist"]/li/div/a[2]/text()')
pattern = re.compile(r"\n+|\s+", re.S) # 查找\n和\s进行替换
users = [pattern.sub('', users[u]) for u in range(1,len(users),2)] # 删除第一个空内容
print(users)
结果:
['好吃的豆苗', '马赛克姑凉', '浅夏°淡雅', '清雅wuda', '肉乎乎的小瘦子', 'dreamer...', '拒绝添加剂',......]
浏览量和收藏量的获取方式是一样的,分别在两个span标签中
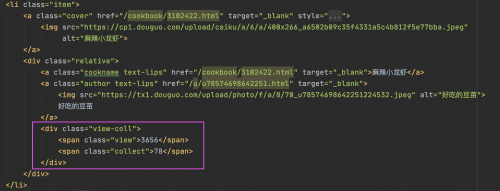
//ul[@id="jxlist"]/li/div/div/span[1]/text() 获取浏览量
//ul[@id="jxlist"]/li/div/div/span[2]/text() 获取收藏量
代码如下:
views = html.xpath('//ul[@id="jxlist"]/li/div/div/span[1]/text()')
print(views)
collects = html.xpath('//ul[@id="jxlist"]/li/div/div/span[2]/text()')
print(collects)
运行结果:
['3656', '1.5万', '1.5万', '3158', '2729', '1.2万', '2.0万', ...... ]
['78', '431', '504', '83', '32', '245', '484',......]
完整代码
以下代码添加了分页的内容,分页的特点是:
https://www.douguo.com/jingxuan/0 第一页
https://www.douguo.com/jingxuan/24 第二页
https://www.douguo.com/jingxuan/48 第二页
.....
import requests
import re
import csv
from lxml import etree
def get_html(page):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
response = requests.get('https://www.douguo.com/jingxuan/' + str(page), headers=headers)
return response.text
def parse_html(content):
html = etree.HTML(content)
links = html.xpath('//ul[@id="jxlist"]/li/a/@href')
images = html.xpath('//ul[@id="jxlist"]/li/a/img/@src')
names = html.xpath('//ul[@id="jxlist"]/li/div/a[1]/text()')
users = html.xpath('//ul[@id="jxlist"]/li/div/a[2]/text()')
pattern = re.compile(r"\n+|\s+", re.S)
users = [pattern.sub('', users[u]) for u in range(1, len(users), 2)]
views = html.xpath('//ul[@id="jxlist"]/li/div/div/span[1]/text()')
collects = html.xpath('//ul[@id="jxlist"]/li/div/div/span[2]/text()')
return zip(names, links, users, views, collects, images)
def save_data(foods):
with open('foods.csv', 'a') as stream:
writer = csv.writer(stream)
writer.writerows(foods)
if __name__ == '__main__':
for i in range(6):
page = i*24
content = get_html(page)
foods = parse_html(content)
save_data(foods)
print(f"第{i+1}页保存成功!")














 京公网安备 11010802030320号
京公网安备 11010802030320号