


什么是B+Tree?
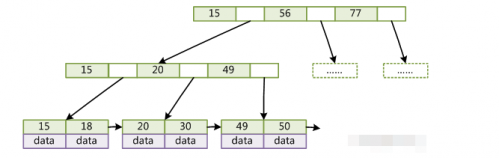
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
为什么是B+Tree?
为了减少磁盘读取次数,决定了树的高度不能高,所以必须是先B-Tree;
以页为单位读取使得一次 I/O 就能完全载入一个节点,且相邻的节点也能够被预先载入;所以数据放在叶子节点,本质上是一个Page页;
为了支持范围查询以及关联关系, 页中数据需要有序,且页的尾部节点指向下个页的头部;
B+树索引可分为聚簇索引和非聚簇索引?
主索引就是聚簇索引(也称聚集索引,clustered index)辅助索引(有时也称非聚簇索引或二级索引,secondary index,non-clustered index)。
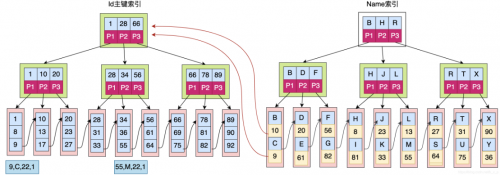
如上图,主键索引的叶子节点保存的是真正的数据。而辅助索引叶子节点的数据区保存的是主键索引关键字的值。
假如要查询name = C 的数据,其搜索过程如下:a) 先在辅助索引中通过C查询最后找到主键id = 9; b) 在主键索引中搜索id为9的数据,最终在主键索引的叶子节点中获取到真正的数据。所以通过辅助索引进行检索,需要检索两次索引。
之所以这样设计,一个原因就是:如果和MyISAM一样在主键索引和辅助索引的叶子节点中都存放数据行指针,一旦数据发生迁移,则需要去重新组织维护所有的索引。

















 京公网安备 11010802030320号
京公网安备 11010802030320号