


对于快照来说,所谓“连拍”就是指连续地做快照。这样一来,快照的间隔时间变得很短,即使某一时刻发生宕机了,因为上一时刻快照刚执行,丢失的数据也不会太多。但是,这其中的快照间隔时间就很关键了。
如下图所示,我们先在 T0 时刻做了一次快照,然后又在 T0+t 时刻做了一次快照,在这期间,数据块 5 和 9 被修改了。如果在 t 这段时间内,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 9 的修改值因为没有快照记录,就无法恢复了。
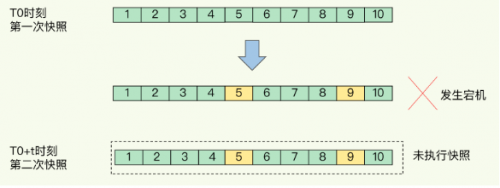
所以,要想尽可能恢复数据,t 值就要尽可能小,t 越小,就越像“连拍”。那么,t 值可以小到什么程度呢,比如说是不是可以每秒做一次快照?毕竟,每次快照都是由 bgsave 子进程在后台执行,也不会阻塞主线程。
这种想法其实是错误的。虽然 bgsave 执行时不阻塞主线程,但是,如果频繁地执行全量快照,也会带来两方面的开销:
一方面,频繁将全量数据写入磁盘,会给磁盘带来很大压力,多个快照竞争有限的磁盘带宽,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环。
另一方面,bgsave 子进程需要通过 fork 操作从主线程创建出来。虽然,子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间越长。如果频繁 fork 出 bgsave 子进程,这就会频繁阻塞主线程了。
那么,有什么其他好方法吗?此时,我们可以做增量快照,就是指做了一次全量快照后,后续的快照只对修改的数据进行快照记录,这样可以避免每次全量快照的开销。这个比较好理解。
但是它需要我们使用额外的元数据信息去记录哪些数据被修改了,这会带来额外的空间开销问题。那么,还有什么方法既能利用 RDB 的快速恢复,又能以较小的开销做到尽量少丢数据呢?RDB和AOF的混合方式。

















 京公网安备 11010802030320号
京公网安备 11010802030320号