


什么是复制集?
保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险。换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载。
在MongoDB中就是复制集(replica set): 一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。
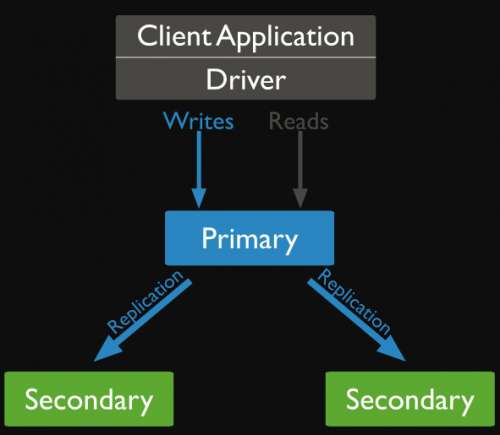
基本的成员?
主节点(Primary) 包含了所有的写操作的日志。但是副本服务器集群包含有所有的主服务器数据,因此当主服务器挂掉了,就会在副本服务器上重新选取一个成为主服务器。MongoDB还细化将从节点(Primary)进行了细化
Priority0 Priority0节点的选举优先级为0,不会被选举为Primary
Hidden 隐藏节点将不会收到来自应用程序的请求, 可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务
Delayed Delayed节点必须是Hidden节点,并且其数据落后与Primary一段时间(可配置,比如1个小时);当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
从节点(Seconary) 正常情况下,复制集的Seconary会参与Primary选举(自身也可能会被选为Primary),并从Primary同步最新写入的数据,以保证与Primary存储相同的数据;增加Secondary节点可以提供复制集的读服务能力,同时提升复制集的可用性。
仲裁节点(Arbiter) Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据。比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。















 京公网安备 11010802030320号
京公网安备 11010802030320号