


通过分步骤看数据持久化过程:write -> refresh -> flush -> merge
write 过程
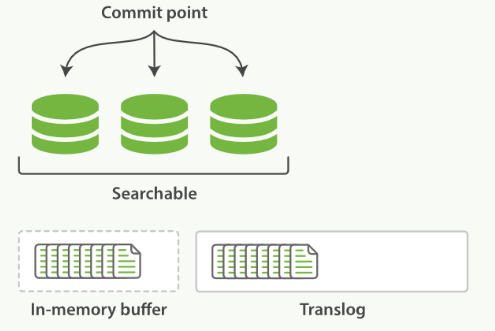
一个新文档过来,会存储在 in-memory buffer 内存缓存区中,顺便会记录 Translog(Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录)。
这时候数据还没到 segment ,是搜不到这个新文档的。数据只有被 refresh 后,才可以被搜索到。
refresh 过程
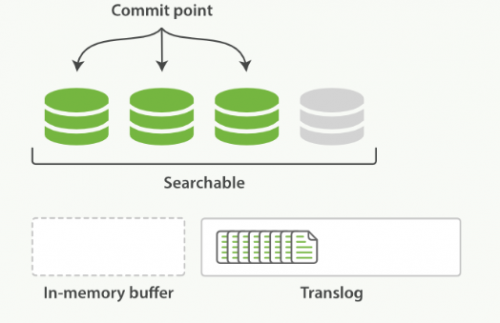
refresh 默认 1 秒钟,执行一次上图流程。ES 是支持修改这个值的,通过 index.refresh_interval 设置 refresh (冲刷)间隔时间。refresh 流程大致如下:
1.in-memory buffer 中的文档写入到新的 segment 中,但 segment 是存储在文件系统的缓存中。此时文档可以被搜索到
2.最后清空 in-memory buffer。注意: Translog 没有被清空,为了将 segment 数据写到磁盘
3.文档经过 refresh 后, segment 暂时写到文件系统缓存,这样避免了性能 IO 操作,又可以使文档搜索到。refresh 默认 1 秒执行一次,性能损耗太大。一般建议稍微延长这个 refresh 时间间隔,比如 5 s。因此,ES 其实就是准实时,达不到真正的实时。
flush 过程
每隔一段时间—例如 translog 变得越来越大—索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行
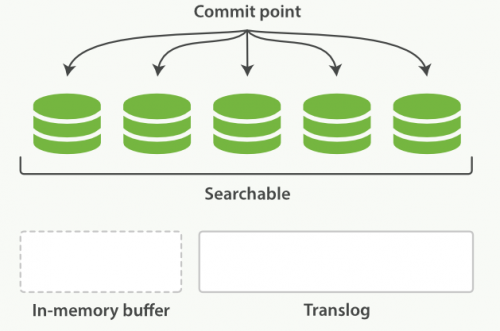
上个过程中 segment 在文件系统缓存中,会有意外故障文档丢失。那么,为了保证文档不会丢失,需要将文档写入磁盘。那么文档从文件缓存写入磁盘的过程就是 flush。写入磁盘后,清空 translog。具体过程如下:
所有在内存缓冲区的文档都被写入一个新的段。缓冲区被清空。一个Commit Point被写入硬盘。文件系统缓存通过 fsync 被刷新(flush)。老的 translog 被删除。
merge 过程
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行Merge Segment来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
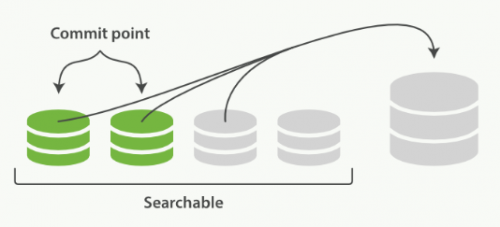
一旦合并结束,老的段被删除:
新的段被刷新(flush)到了磁盘。 ** 写入一个包含新段且排除旧的和较小的段的新提交点。新的段被打开用来搜索。老的段被删除。
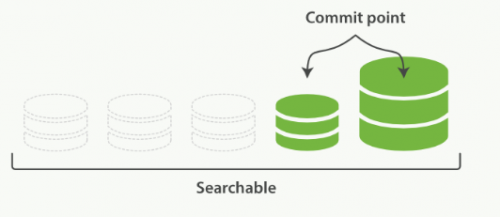
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。















 京公网安备 11010802030320号
京公网安备 11010802030320号