


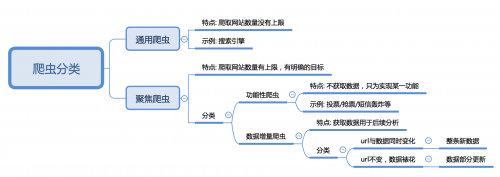
通用爬虫:
通用网络爬虫从互联网中搜集网页,采集信息,这些网页信息决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果
大家要注意哦,通用爬虫虽然简单,方便,但是缺点也是显而易见的,小助手给大家列举了几点,大家可以了解一下:
a.通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
b.不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
c.万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
d.通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
聚焦爬虫:
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息, 如12306抢票,或专门抓取某一个(某一类)网站数据
根据是否以获取数据为目的,可以分为:
• 功能性爬虫,给你喜欢的明星投票、点赞
• 数据增量爬虫,比如招聘信息
根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
• 基于url地址变化、内容也随之变化的数据增量爬虫
• url地址不变、内容变化的数据增量爬虫














 京公网安备 11010802030320号
京公网安备 11010802030320号